
AI Agent Memory Architecture
Memory in AI Agents: What It Is, How It Breaks, and What to Do About It.

The LLM you’re building on has no memory. I am sure you all know that already. Every call to the model is a fresh start. If your agent appears to remember something, that’s because you built a system around the model that stores and retrieves information and injects it back into the prompt. The model itself is stateless.
So when your agent starts giving wrong answers at scale don’t look for the failure in the model. It’s in the memory system you built around it. And if you don’t understand the memory types and how they behave differently under load, you’ll spend weeks debugging the wrong layer. I have seen this happen multiple times.
Why Memory Architecture Is the Real Work
Consider what happens in a real production deployment at a financial institution. An agent handles customer queries across thousands of sessions per day. It needs to know what the customer asked last week. It needs to know current product terms. It needs to know what it did three steps ago in the current task. It needs to know that when a customer says “the same account as before,” they mean their savings, not their current account.
These are four completely different information retrieval problems. Treating them as one (which is what happens when teams reach for a vector database and call it done) is where agents fall apart in production.
Each of these problems maps to a distinct memory type. Each type has different latency characteristics, different staleness risks, different failure modes, and different architectural requirements.
The Four Types of Agent Memory
1. In-Context Memory (Working Memory)
This is whatever sits inside the current context window - the active prompt, the conversation so far, the instructions, the retrieved chunks, the tool outputs. It’s the only memory the model can directly reason over.
What it’s good for: The current task. Right now. This session.
Constraint: Context windows are finite. GPT-4o gives you 128K tokens. Claude gives you 200K. They sound large until you’re injecting retrieved documents, conversation history, system instructions, and tool schemas simultaneously. You will always burn through context faster than you would expect.
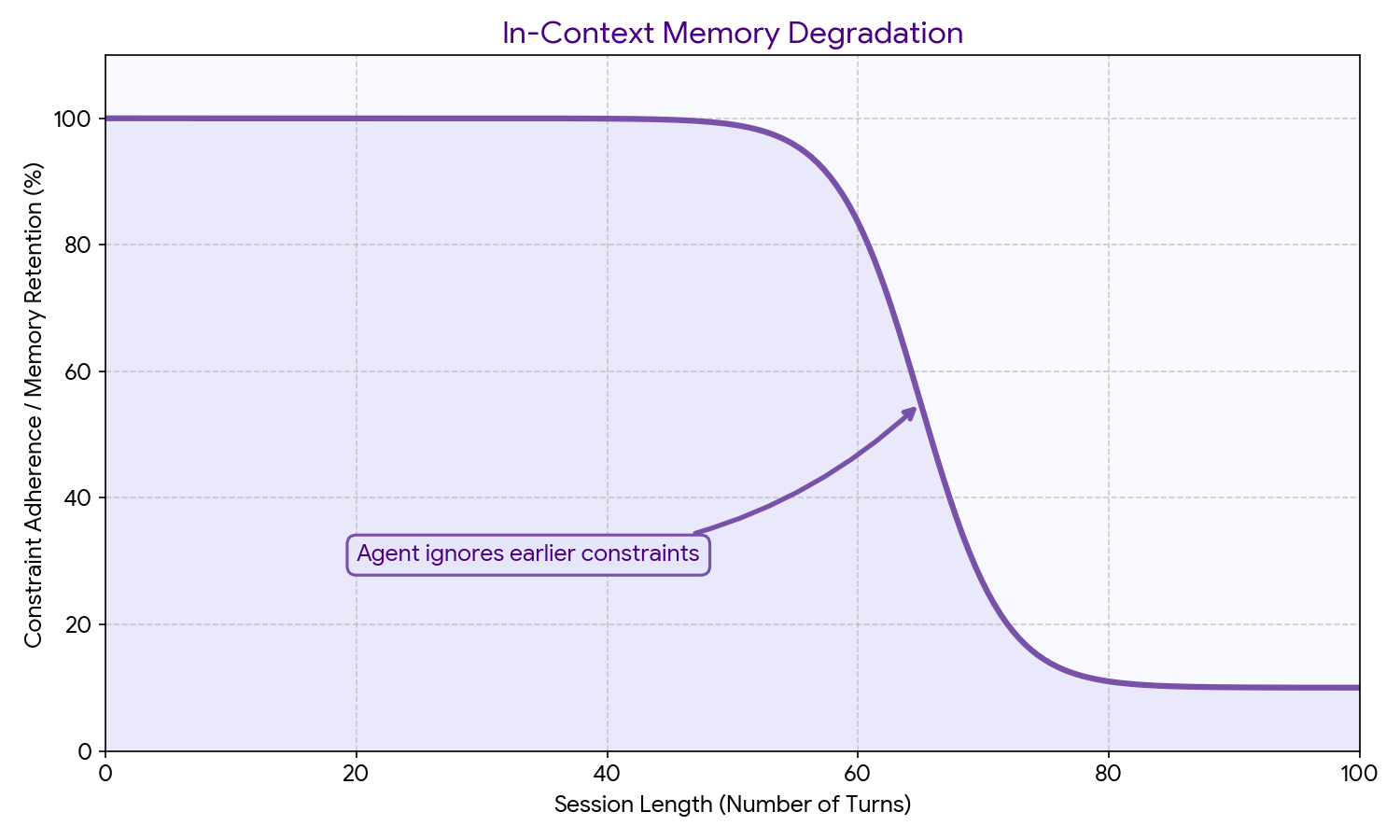
Failure pattern: Teams usually design for a 10-turn conversation in testing. Real users run 60-turn sessions. Context fills up, older turns get truncated, and the agent loses track of earlier constraints the user set. The agent doesn’t tell the user it’s forgotten. It just starts behaving inconsistently. And that’s dangerous.
2. Episodic Memory (What Happened)
This is the log of past interactions - previous conversations, completed tasks, decisions made, outcomes observed. It’s stored externally and retrieved when relevant.
What it’s good for: Cross-session continuity. “Last time we spoke, you were working on the credit risk model.” Personalisation. Audit trails in regulated environments.
Implementation: Conversation summaries or raw turns get embedded and stored in a vector database. At the start of each new session, a semantic search retrieves the most relevant past episodes and injects them into context.
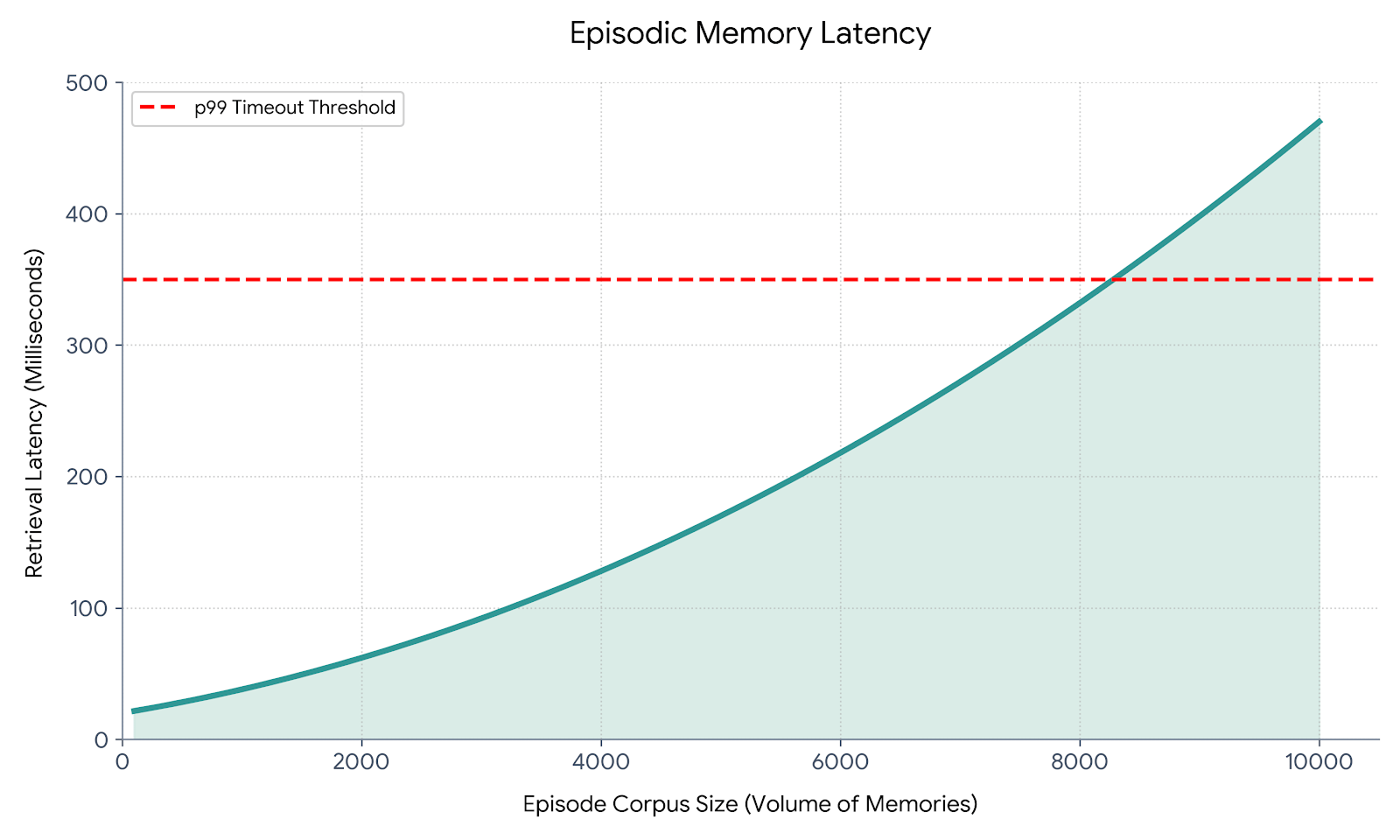
Failure Pattern: Episodic memory grows without bound. A user with 200 past sessions generates thousands of stored chunks. Retrieval latency climbs. Relevance degrades because older episodes are returned alongside recent ones. Teams don’t notice until p99 latency starts causing timeout errors in production.
3. Semantic Memory (What Is Known)
This is factual, reference knowledge - product documentation, policy documents, regulatory guidance, knowledge base articles. It doesn’t change per user. It’s the shared ground truth the agent reasons from.
What it’s good for: Answering questions from authoritative sources. Think everything about the business. Grounding the agent in facts rather than hallucination. RAG (Retrieval Augmented Generation) is almost always semantic memory.
Implementation: Documents are chunked, embedded, and indexed. Queries are embedded and matched via similarity search. Top-K chunks are injected into context.
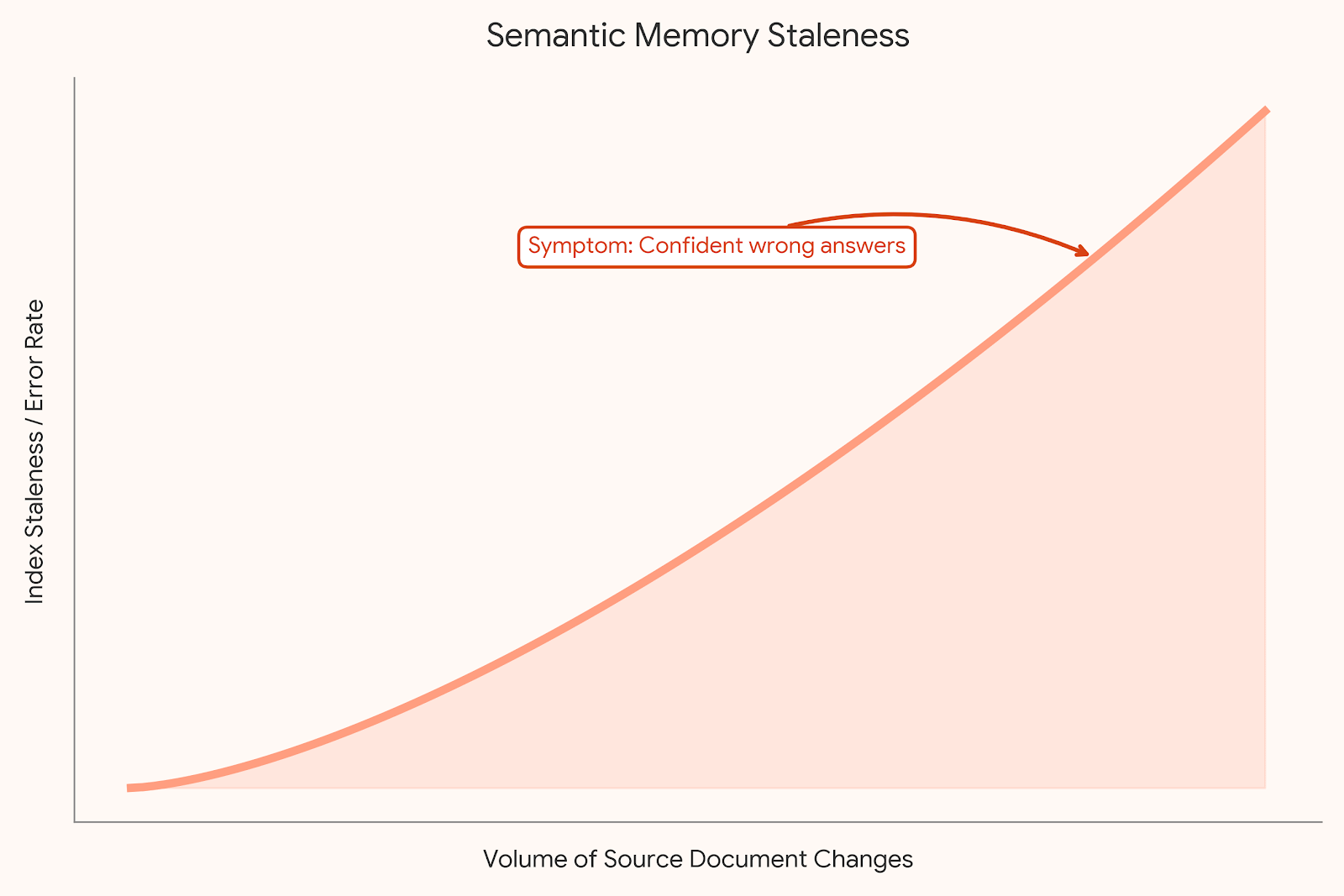
Failure Pattern: Source documents change, the index doesn’t (this is very common). Nobody set up a re-indexing trigger. The agent retrieves a policy document from eight months ago with full confidence, because from the vector database’s perspective it’s still the most semantically similar result. In a regulated environment, this isn’t a UX problem. It’s a compliance problem with vulnerabilities that can cause huge penalties.
4. Procedural Memory (How to Act)
This is the agent’s knowledge of how to behave - which tools to call, in what order, under what conditions. It’s not retrieved at runtime in the same way the other types are. It’s encoded in the system prompt, in tool schemas, in fine-tuned weights, or in explicit workflow definitions.
What it’s good for: Consistent behaviour across all users and sessions. If you want the agent to always verify identity before accessing account data, that’s procedural memory.
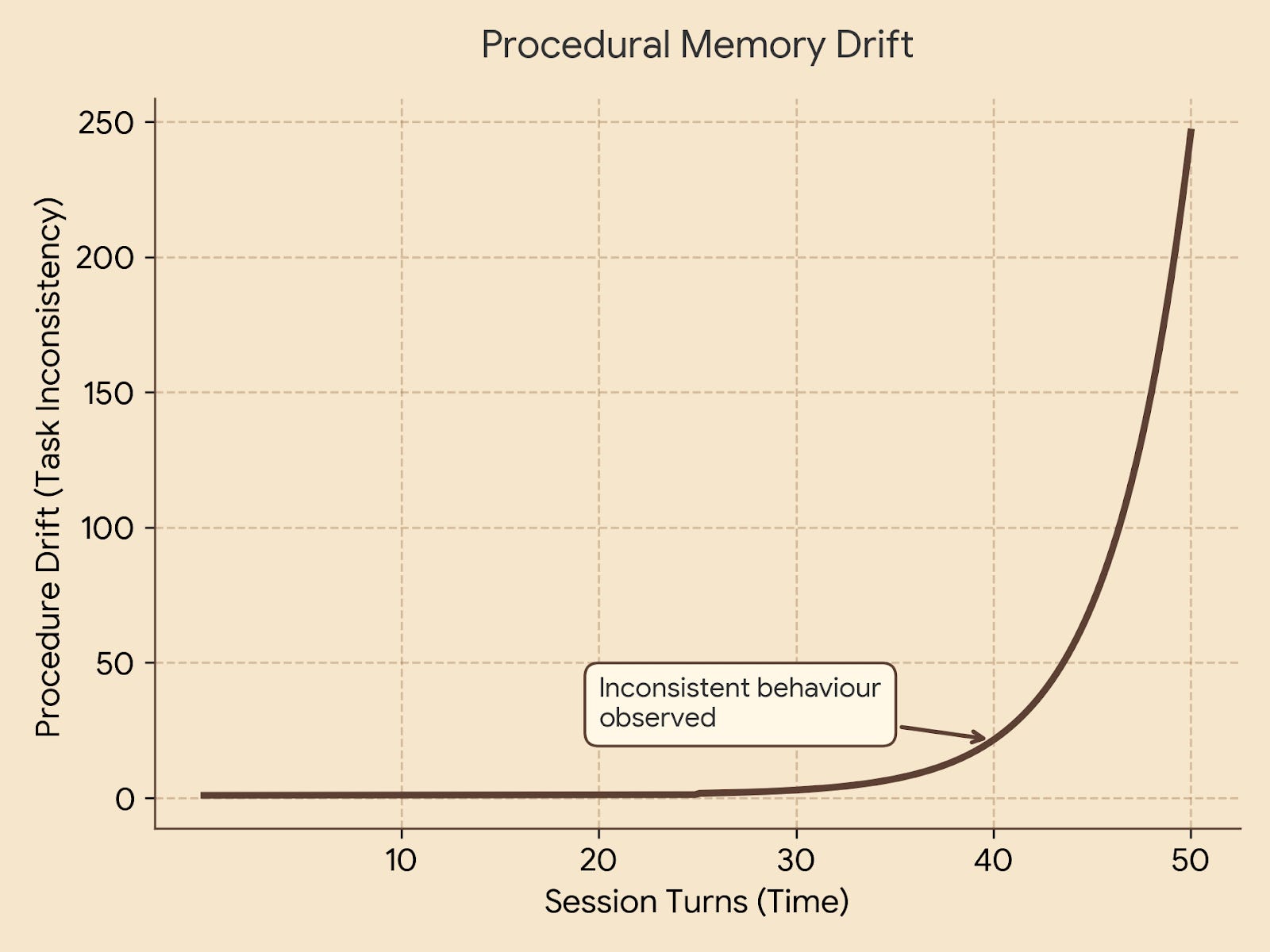
Failure Pattern: Procedural memory encoded only in system prompts is brittle. Long system prompts get partially ignored as context fills. Behaviour drift emerges - the agent follows the procedure at the start of a session but deviates by turn 40. Teams don’t catch this because they test short sessions.
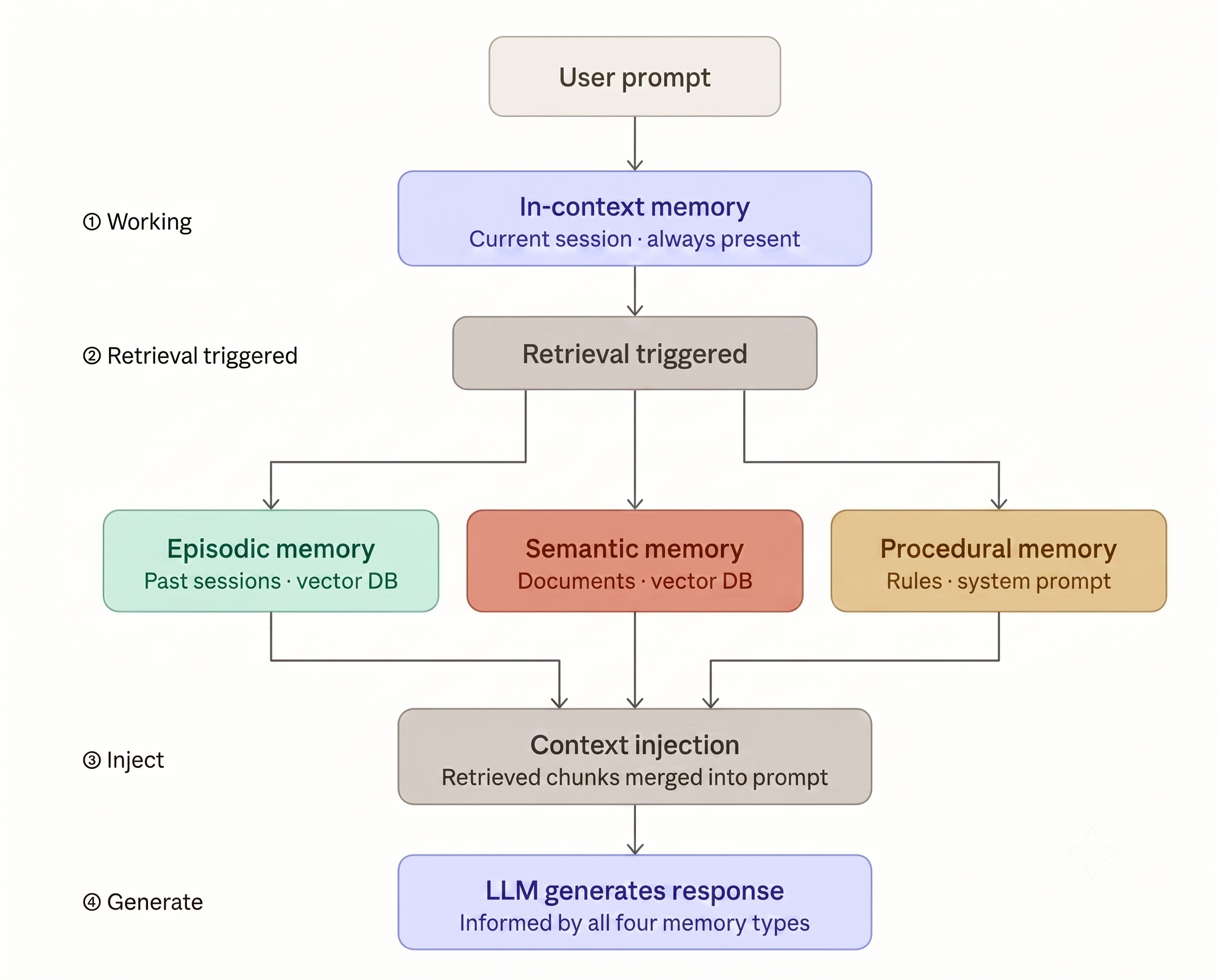
How These Four Types Behave Differently at Scale
At low volume , say hundreds of sessions per day, all four types can be bolted onto a single vector database and it mostly works. At production scale, i.e., tens of thousands of sessions, millions of stored episodes, documents updating continuously, each type starts failing in a distinct way.
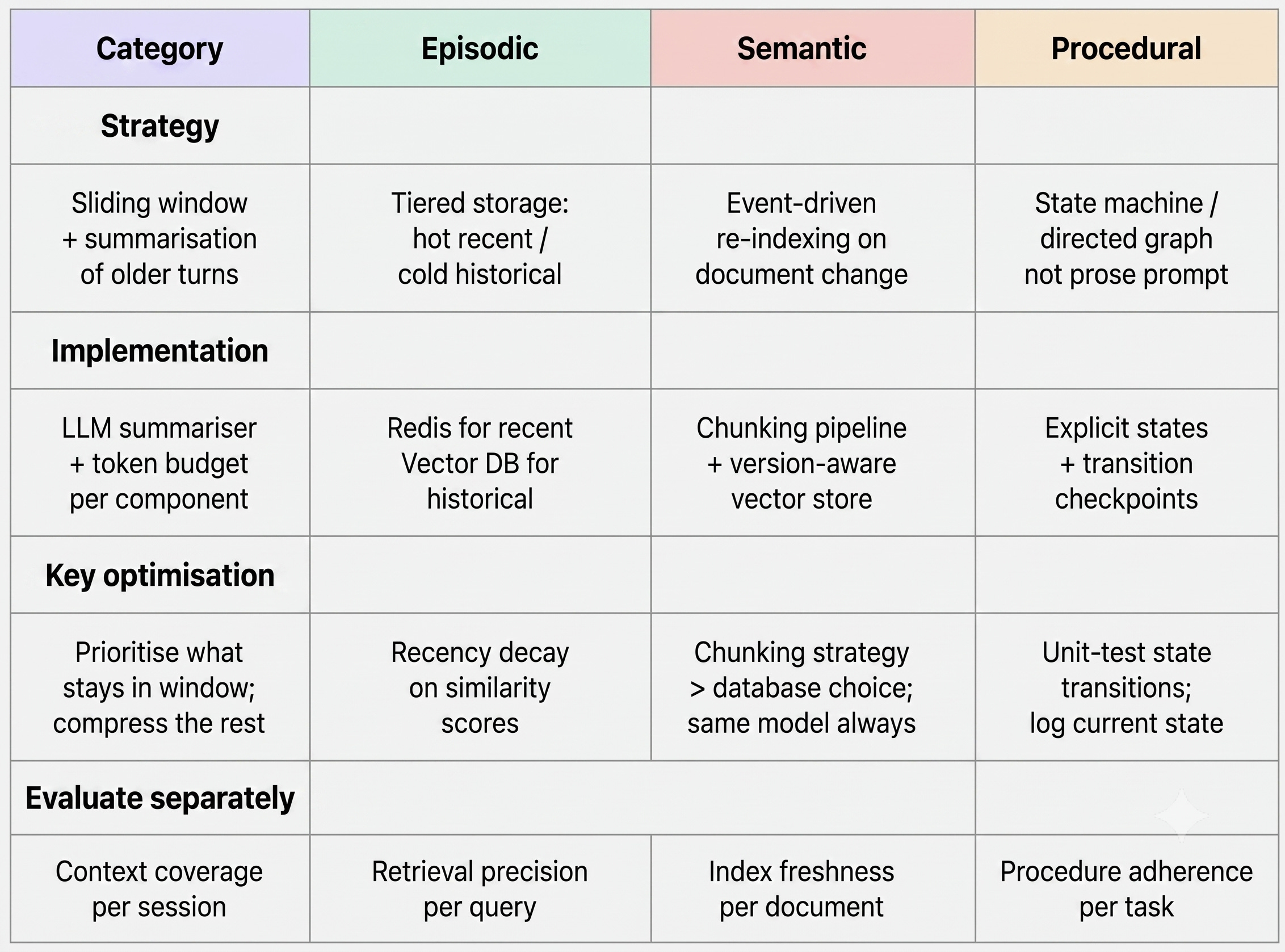
In-context memory degrades with session length. The longer the conversation, the more context is consumed, and the more the model has to work with a truncated window. At scale, you need a context management strategy: summarise older turns, compress tool outputs, prioritise what stays in window.
Episodic memory degrades with corpus size. Retrieval latency grows as the episode store fills. Relevance drops as more episodes compete for the same top-K slots. At scale, you need a tiered storage strategy: hot storage for recent episodes (last 30 days), cold storage for older ones, with a recency-weighted retrieval model rather than pure semantic similarity.
Semantic memory degrades with document churn. The faster your source documents update, the faster your index goes stale. At scale, you need event-driven re-indexing triggered by document changes, not scheduled batch re-indexing that runs weekly and misses the update that happened on Tuesday.
Procedural memory degrades with task complexity. Simple, short tasks follow procedures reliably. Long, multi-step tasks in complex domains show drift. At scale, you need procedures encoded as explicit workflow graphs - not just prose in a system prompt - with checkpoints that verify the agent is still on the correct path.
Architecture Choices and Optimisation Strategies
For in-context memory:
A common pattern is to use a sliding window with summarisation. Keep the last N turns verbatim, summarise everything older into a compressed context block. If you use Claude Code - you will notice it does that in long conversations. It compresses conversations at one point. (Yes, Claude Code is an agent).
LLM-generated summaries work well here. For long-running agents, implement a context budget - allocate token limits per component (system instructions, retrieved memory, conversation history, tool outputs) and enforce them at the orchestration layer, not as an afterthought.
For episodic memory:
Separate your recent episode store from your historical episode store. Redis or a fast key-value store handles recent sessions; your vector database handles historical retrieval. I love Databricks LakeBase architecture here - LakeBase can act as the transactional store while the historical data is stored in Delta Lake. (I know Databricks plug, but it is usful to know if you are already using Databricks).
Apply recency decay to your similarity scores - an episode from yesterday should score higher than a semantically identical episode from six months ago, because context drifts. Build a summarisation pipeline that condenses completed sessions before storage, rather than storing raw turns.
For semantic memory:
Your chunking strategy is your most important decision - more important than your choice of vector database. Chunks need to be semantically coherent, not just fixed-size token windows. 512 tokens with sentence boundary respect and document-level metadata outperforms 2048-token sliding windows without metadata. Build a document change detection pipeline that triggers re-embedding on update. Track embedding model versions - if you upgrade your embedding model, you need to re-embed your entire corpus, because old and new vectors aren’t comparable.
For procedural memory:
Move away from text prose system prompts for complex procedures. Define agent behaviour as a state machine or directed graph - explicit states, explicit transitions, explicit conditions. This gives you auditability (you can log which state the agent was in at each step), testability (you can write unit tests for state transitions), and recoverability (you can restart a failed task from a known state rather than from the beginning).
You know what’s common across all four?
Each memory type needs its own evaluation pipeline.
Not just evaluation of the agent’s final output - evaluation of the memory layer itself. Did episodic retrieval return the right sessions? Did semantic retrieval return current documents? Did the agent follow the correct procedure? Did context management preserve the right information?
They need to be measured separately. And at production scale, not doing this could prove expensive, and risk reputational damage.
Now, tell me what kind of memory failure patterns you observed in your implementations. Give me feedback - tell me how this article helps you. I want to hear more from you.
If you love listening to experts, this podcast with Denis Rothman, author of Context Engineering for Multi-Agent Systems is very relevant. Denis is a thoughtleader and he describes complex topic in simple human way. You will like it.
Talk soon,
Sandi.
P.S. If you’re new here - welcome 🎉. AgentBuild is a community of practitioners working through the real challenges of getting AI into production inside large organisations. Every week I share practical, grounded thinking from the people doing this work at the sharp end. The goal is never theory - it’s always: what can you use Monday morning.
Talk soon,
Sandi.
Ask your friends to join.
More valuable content coming your way.