
Chapter 2: Why your AI Agents will struggle?
How data products can save them (or sink them)?

I was not very optimistic about adoption of AI agents in 2024. However, I must admit, the rate of adoption is increasing exponentially. Today, agentic adoption is mostly behind software products, like Cursor, Lovable, etc. however, AI agents built in-house are entering production environments faster than most data platforms are ready for. In practice, many agent deployments are either stalling or underperforming, often because the supporting data infrastructure isn’t designed for autonomous execution.
This post addresses a root cause: the gap between how data products are currently built and what agentic AI systems actually need. It outlines a prescriptive approach for designing data products that support agentic AI systems, based on my discussions with enterprises.
Agents are not consumers, they are decision executors
Currently data teams building data products build them with human consumers in mind. Humans explore, interpret, and question the data before acting. Agents don’t.
AI Agents are autonomous components executing policies, optimizing state transitions, or negotiating outcomes with other agents. They operate under strict latency and reliability constraints. If their upstream data source is stale, malformed, or lack necessary context, their behavior degrades immediately.
Agents require input data that is latest, contextual and semantically reliable. Anything less introduces systemic inefficiencies.
Traditional data platform thinking falls short
The data product frameworks I have seen so far emphasize reusability, discoverability, and stakeholder value alignment. Those are useful, but insufficient for agentic AI.
The following constraints apply in agentic systems:
Data must be consumable in real time via well-structured APIs or streaming interfaces. Batch pipelines and semi-structured data lakes are not viable for high-frequency decision-making.
Schema evolution must be tightly governed. Agents cannot tolerate unexpected field changes, invalid formats, or missing values.
Contextual metadata must be embedded, not documented externally. This includes units, timezones, versions, and tolerances.
The table below summarizes the constraints for agents and the impact of not adhering to agent requirements.
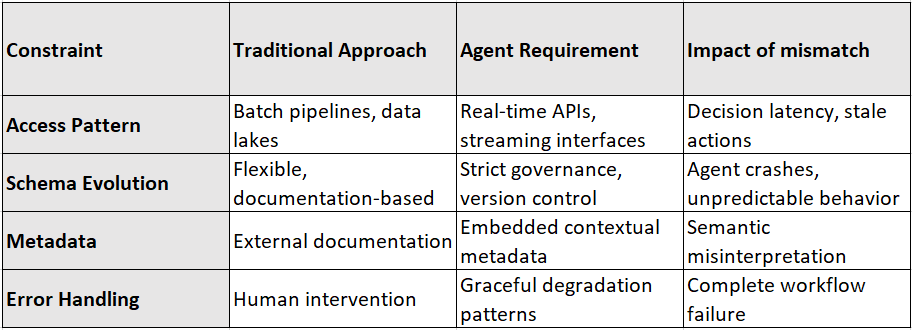
Failure to meet these requirements results in either agent failure (crashes, degraded behavior) or human re-involvement. This erodes the benefit of autonomy.
I’ll use a couple of examples to explain how data products can make or break an agentic behaviour.
Example 1: Data products driving successful agent execution
A logistics company used AI agents for optimization of a global delivery network. They deployed AI Agents to continuously re-optimize vehicle routing using traffic, weather, and facility availability data. Initial results were poor, agents produced conflicting routes and latency-sensitive decisions failed.
In the snippet below, you can see how different formats and context results in inconsistency, falling back to manual override.
Note: The code snippets in this blog are conceptual, not for deployment.
// Before: Problematic multi-source data integration
function optimizeRoutes(vehicleIds, deliveryLocations):
// Get data from multiple disconnected sources with different update frequencies
locations = getLocationData() // Updated daily from data lake
traffic = getTrafficConditions() // Updated every 15 minutes
weather = getWeatherConditions() // Updated hourly
vehicles = getVehicleStatus() // Updated every 5 minutes
depots = getDepotAvailability() // Updated twice daily
// Different time formats across systems
// locations use YYYY-MM-DD
// traffic uses Unix timestamps
// weather uses ISO8601 but in EST timezone
// vehicles use ISO8601 in UTC
// depots use 12-hour time format with AM/PM
// Different coordinate systems
// locations use lat/long
// traffic uses road segment IDs
// weather uses grid cells
// Attempt to reconcile and normalize data
try:
normalizedData = reconcileDataSources(
locations, traffic, weather, vehicles, depots
)
// Multiple agents making decisions with different data freshness
for vehicleId in vehicleIds:
// Each agent gets slightly different view of world
agent = getAgentForVehicle(vehicleId)
route = agent.planRoute(normalizedData, deliveryLocations)
assignRoute(vehicleId, route)
catch DataInconsistencyError:
// Fall back to manual routing
notifyDispatcher("Automated routing failed, manual intervention required")
return getManualRoutes()How did they resolve it?
They rebuilt location, transit, and depot data into unified data products aligned with the agent requirements.
Data is delivered via low-latency API with strict schema contracts and freshness guarantees.
They added time-normalization and context fields (e.g., delay tolerances, routing constraints).
// After: Unified data products with strict schema control
function optimizeRoutes(vehicleIds, deliveryLocations):
// Single request to unified routing data product API
routingContext = dataProducts.getRoutingContext({
vehicleIds: vehicleIds,
region: calculateRegion(deliveryLocations),
timeWindow: {start: now(), end: now() + hours(8)},
requiredDataSets: ["locations", "traffic", "weather", "vehicles", "depots"]
})
// Validate all data meets freshness requirements
if (!routingContext.validateFreshness()):
// Graceful degradation with clear reason
return createConservativeRoutes(
vehicleIds,
deliveryLocations,
routingContext.getFreshDataSets()
)
// All agents use same consistent view of world
sharedWorldView = routingContext.getWorldView()
// Schema validation ensures all required fields exist
// All coordinates normalized to same system
// All timestamps normalized to UTC ISO8601
// All data includes confidence scores
routes = []
for vehicleId in vehicleIds:
agent = getAgentForVehicle(vehicleId)
// Each agent works with identical data
route = agent.planRoute(sharedWorldView, deliveryLocations)
routes.push(route)
// Validate routes don't conflict
conflicts = detectRouteConflicts(routes)
if (conflicts.length > 0):
// Resolve conflicts with clear rules
routes = resolveConflicts(routes, conflicts, sharedWorldView)
// Assign final routes
for i in range(vehicleIds.length):
assignRoute(vehicleIds[i], routes[i])
return routesResult:
Agents only achieved true autonomy when the data product finally aligned with their operational constraints. Once that happened, something clicked. They began to converge on consistent plans. Delivery latency dropped by 12% and manual overrides dropped. You can’t achieve autonomy with smart AI agents. You need to give them the right data, in the right shape, at the right time.
Example 2: Data products causing agent failures
A financial services company implemented compliance automation in a regulated enterprise. AI agents were tasked with monitoring transaction data and recommending flagging actions based on internal policies and regulatory thresholds.
// Example of problematic data product response
{
"transactions": [
{
"id": "TX123456",
"amount": 50000,
// Missing currency specification
"timestamp": "2025-03-15",
// Ambiguous timestamp format (no time zone)
"risk_score": 0.75
// No context on what risk score means or threshold
}
]
// No schema version or freshness metadata
}The data team deployed a suite of well-documented compliance datasets as discoverable data products. But agent behavior quickly broke down:
Data was updated in daily batches, violating the agent's sub-hour SLA
Thresholds and risk indicators were undocumented or inconsistently encoded
No contract enforcement existed across schema changes
// Example of agent-ready data product response
{
"transactions": [
{
"id": "TX123456",
"amount": 50000,
"currency": "USD", // ← Explicit currency specification
"timestamp": "2025-03-15T14:22:31.456Z", // ← ISO 8601 format with timezone
"risk_score": 0.75,
"risk_thresholds": { // ← Context for interpreting risk score
"low": 0.3,
"medium": 0.6,
"high": 0.8
},
"regulatory_categories": ["large_transaction", "domestic"], // ← Domain-specific context
"requires_review": false, // ← Direct actionable signal for agent
"confidence": 0.92 // ← Quality indicator for decision-making
}
],
"metadata": { // ← Separate metadata section
"schema_version": "3.2.1", // ← Explicit schema versioning
"generated_at": "2025-03-15T14:22:35.123Z", // ← When this data was created
"data_freshness_seconds": 240, // ← How fresh the data is
"sla_seconds": 3600, // ← Service level agreement
"source_systems": ["core_banking", "risk_engine"], // ← Provenance tracking
"next_update_at": "2025-03-15T14:27:35.123Z" // ← Predictable update schedule
}
}Result:
The agents couldn’t execute their intended policy logic. Human teams had to step in and correct the failures, creating even more work. In the end, the entire agentic implementation had to be paused while they reworked the data pipeline. You see, even high-quality data products aren’t enough for agent-driven workflows. Agents need data delivered on time, with tight schema control. Without that, autonomy breaks down before it begins.
What agentic data products must deliver?
A data product is only agent-ready if it supports autonomous execution across the following dimensions:
1. Purpose-bound design
Each data product must align with a specific decision point in an agent’s policy or reasoning loop. If the data does not contribute to a concrete decision boundary, it should not be included in the system.
Checklist:
Does the agent consume this product to alter its state, goal prioritization, or policy branch?
Is this the primary input to that decision, or one of many?
If removed, does the agent’s behavior break or degrade?
If the answer to these questions is “no,” the data product is unnecessary or misaligned.
2. Strict schema contracts and validation
Agents can easily break with structural drift of data. Adding a field, changing a type, or reordering elements without validation can corrupt downstream execution or introduce silent failures.
Implementation detail:
Use schema registry and contract enforcement at the pipeline level (read about data contracts)
Include automated test coverage for agent consumption paths
Blocks deployment when schema changes are not explicitly versioned and backward compatible
// Using a schema validation approach class LocationCoordinate: properties: latitude: number (required, range: -90 to 90) longitude: number (required, range: -180 to 180) coordinateSystem: string (default: "WGS84") accuracyMeters: number (optional) class Location: properties: id: string (required) name: string (required) coordinates: LocationCoordinate (required) lastUpdated: timestamp (required) isActive: boolean (default: true) metadata: version: "1.2.0" deprecatedFields: [] addedSinceLastVersion: ["accuracyMeters"] // API endpoint with validation function getLocation(locationId): try: rawLocation = locationService.getLocation(locationId) // Validate against schema location = validateAgainstSchema(rawLocation, Location) return location catch ValidationError as e: // Log schema violation for observability recordSchemaViolation( dataProduct: "locations", errors: e.details ) return { error: "Schema validation failed", details: e.details }
3. Latency-appropriate access patterns
Agents operate on different decision time horizons. Some react in milliseconds, others in minutes. Data products must match this operational cadence via appropriate interfaces. In the table below I have mapped out the different types of AI agents to the data access methods they use, the data product requirements they depend on, and example implementations. It shows you how real-time, planning, and reflective agents need different data architectures to function effectively.
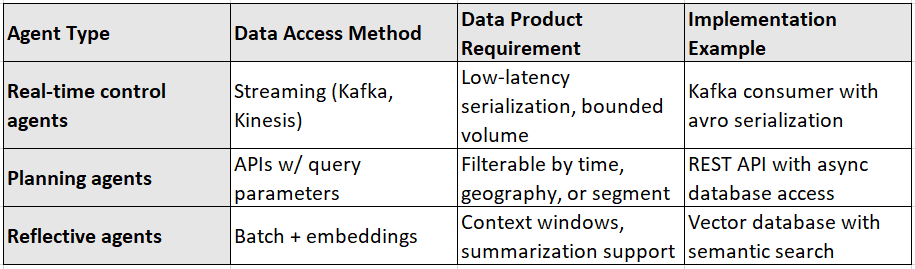
Afterall, you wouldn’t want to serve time-sensitive agents via batch loads or object storage reads.
4. Embedded context and semantic fidelity
Data products lacking semantic fidelity create ambiguity, which agents cannot resolve. Agents need to reason from context, not raw values. This requires that semantic information, such as units, time zones, and acceptable variance, is baked into the structure, not written in external documentation.
Example: A field called
balanceis unusable unless:
Currency is defined
Time snapshot is explicit
Normalization logic is applied
To include semantic information into data product structures, consider extending basic data types to include domain-specific types (custom) with built-in units, validation rules, and conversion logic.
5. Observability of agent-data interactions
Observability is essential because agents act without human oversight. Without visibility into how they interact with data, you will never know what’s going on until something goes wrong. You need to know which data was used, how it influenced decisions, and whether it met expected quality standards.
You must be able to answer:
Which agents accessed which data products?
Were results deterministic?
Did schema mismatches or data freshness violations occur?
Consider the following in your design process:
Access logging with identity-level tracing
Data drift detection and rollback triggers
Metric-based thresholds for confidence scoring (e.g., missing fields > X%)
Observability turns silent failures into actionable signals for improving reliability and trust in autonomous systems.
Organizing teams for success
Building agentic-ready data products requires organizational re-arrangement. This is a big topic and I intend to cover it in a separate blog. Building data products is almost like building software products, and that means you need the right processes and right people in place to delivery them.
Product owners must understand agent workflows. Assigning a PM who only understands business reports or dashboards will result in misaligned products. You will need to upskills your product owners to understant agentic systems.
Data governance must operate at the contract level, not just cataloging. Versioning, validation, and SLAs must be enforced across the runtime lifecycle. Think how you can operationalize this through DataOps patterns.
Feedback loops from agents must inform product evolution. Treat agents as users whose logs, errors, and behavior offer critical feedback. This is important as it informs data product roadmap, and provide valuable insights into prioritization of work.
Without these structures, even the most technically sound data architecture will fail to support agent autonomy.
Final Notes
Building agentic AI without rethinking your data architecture is not a good idea. it is like deploying autonomous vehicles with paper maps. You don’t need more data to successfully deliver agetic outcomes. You need fewer, more precise, and contract-compliant data products that are tied to the decisions your agents actually make.
When properly designed, data products are not just passive infrastructure. They become active control surfaces in agentic systems that enable machines to reason, act, and coordinate without human intervention.
When poorly designed, they are the most expensive form of technical debt: invisible, foundational, and corrosive to trust and performance.
Start with decision alignment. Enforce contracts. Optimize for latency and fidelity. Then scale.
Coming Next:
In Chapter 3, I’ll share a hands-on evaluation framework for assessing whether your existing data products are agent-ready including maturity model, architectural templates and team roles.
If you’re working on agentic systems today, I’d like to hear how you’re aligning data infrastructure. Contact me or reply to this post with your questions.