
Chapter 3: Is your Data ready for AI Agents? A Hands-on Framework to find out
Understand the maturity stages, spot hidden gaps, and prepare your data for the next wave of enterprise AI

Introduction
The more I speak with enterprise leaders, the clearer it becomes: Agentic AI is still early. Despite the buzz of 2025, real implementation of agentic AI in enterprise workflows is nascent. Don’t buy into social media hype.
That said, enterprises are thinking ahead, Gartner predicts that by 2028, 33% of enterprise software will embed agentic AI, enabling 15% of daily work decisions to be made autonomously. Yet challenges remain: research from Architecture & Governance magazine shows 49% of practitioners cite data governance issues as a major barrier. Technical hurdles like integration complexity, poor data quality, and infrastructure gaps are common. As I discussed in Chapter 2, data products built for human consumption often break down when used by agents, creating a gap between ambition and reality.
This blog introduces a hands-on evaluation framework to assess your data products' agent-readiness. Use it as a reference guide to identify gaps, and build a roadmap toward agent-optimized data infrastructure.
Maturity Model: Data Products for AI Agents
To systematically improve data for AI agents, we define four maturity levels: Human-Oriented, Agent-Compatible, Agent-Optimized, and Agent-Native. Each level represents a significant step-change in how a data product is designed, delivered, and governed for AI consumption. Figure 1 provides a high-level illustration of these stages.
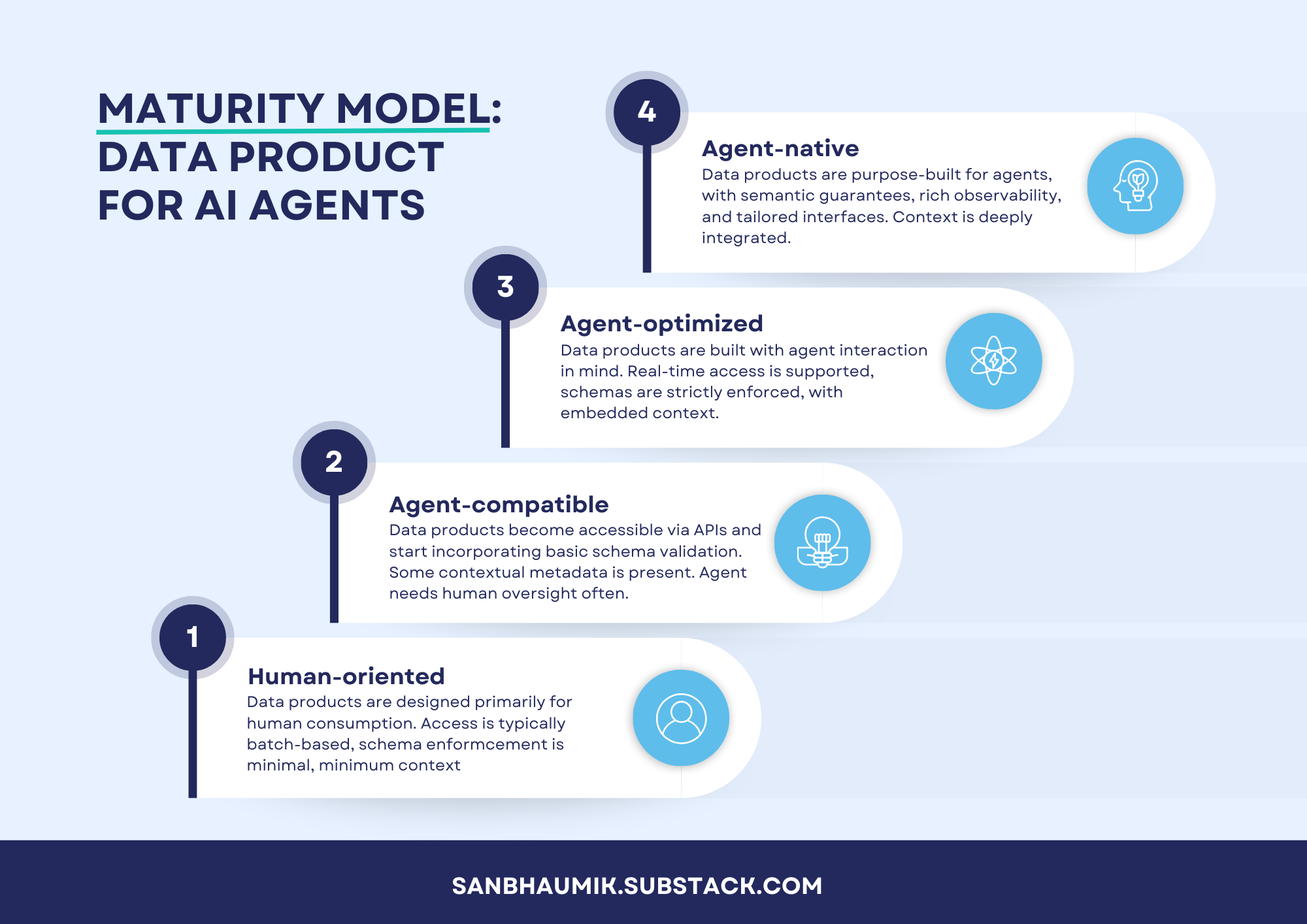
Figure 1: Maturity Model – Data Product for AI Agents. This four-level model shows the evolution from Human-Oriented (Level 1) to Agent-Native (Level 4) data products, with increasing capability for autonomous AI consumption at each stage.
Let’s briefly characterize each maturity level:
Level 1: Human-Oriented
At this baseline stage, data products are designed primarily for human consumption. Data might be delivered as batch reports, dashboards, or CSV extracts. Access is often manual or batch-oriented (e.g. nightly SQL dumps or scheduled reports). Schema enforcement is minimal – the data may be loosely structured or inconsistently formatted, since human consumers can adapt on the fly. Context/metadata is rare; a human user relies on tribal knowledge or separate documentation to interpret the data. In short, the data product works for a person with expertise, but an AI agent would struggle to use it without human help. This is where I see most organizations today.Level 2: Agent-Compatible
At this stage, data product teams recognize the need to support programmatic access. The data product becomes accessible via APIs or data services, not just static files. For example, a REST endpoint or SQL query interface is provided so that applications (or simple agents) can fetch the data. Basic improvements appear: schema validation is introduced to ensure the data conforms to expected structure, reducing surprises for consumers. Some contextual metadata is added – e.g. data fields have descriptions, or there is basic documentation about the dataset. The data product is still not heavily optimized for AI – an agent can get data, but might still need human oversight to configure queries or handle errors. Nonetheless, the foundation is laid: machine consumption is possible, albeit with limitations. I work with software companies mostly, and I can see many of my customers already at this stage. Their business model often demands them to provide programmatic access to data.Level 3: Agent-optimized
Here the data product is intentionally designed for agent interaction. Real-time or on-demand access is supported; for instance, low-latency APIs, streaming endpoints, or event feeds enable an AI agent to get fresh data whenever needed . Strict schemas and data contracts are enforced – producers and consumers (human or AI) have a clear agreement on the data structure, semantics, and quality rules. Context is embedded - rich metadata accompanies the data (such as units, definitions, relationships to other data), often accessible through the same API or a linked catalog. The data product might integrate with semantic layers or ontologies so that an AI agent can understand domain concepts (for example, knowing that “product ID” in one dataset is the same as “item code” in another). At this level, an AI agent can reliably query the data product and integrate it into its reasoning with minimal human help. The focus is on performance, reliability, and clarity – so agents can trust and efficiently use the data.Level 4: Agent-Native
This is the cutting edge. Data products at this level are purpose-built for AI agents, treated almost like services for AI rather than datasets. They come with semantic guarantees – meaning the data product not only has a schema, but conveys meaning in a way an AI can interpret unambiguously (e.g. a knowledge graph or detailed ontology is integrated, providing context and business logic). Rich observability is in place – the data product emits detailed telemetry, logs, and quality metrics that both engineers and AI agents could leverage. Tailored interfaces might exist for AI usage, such as a specialized GraphQL query interface or even a natural language query layer tuned for the AI agent. Context is deeply integrated - the data product provides not just data, but knowledge - it might proactively serve relevant context or embed data in a form directly consumable by agents (like vector embeddings alongside raw data for use in retrieval-augmented generation). At this stage, an AI agent can interact with the data product fully autonomously, and even feedback loops may exist (e.g. the agent can signal data errors or request refinements, achieving a self-optimizing system). This is the ideal for AI-first organizations – data products and AI agents working in concert with minimal friction.
In summary, the evolution is from data products that only humans can use (Level 1) to those that actively empower AI agents (Level 4). Each level builds on the previous: you can’t simply jump to Agent-Native without laying the API, schema, and metadata groundwork. Most organizations today find themselves around Level 1 or 2 and are striving to reach 3 or 4 as AI initiatives expand.
To get a quick comparative view, Table 1 outlines key characteristics at each maturity level:
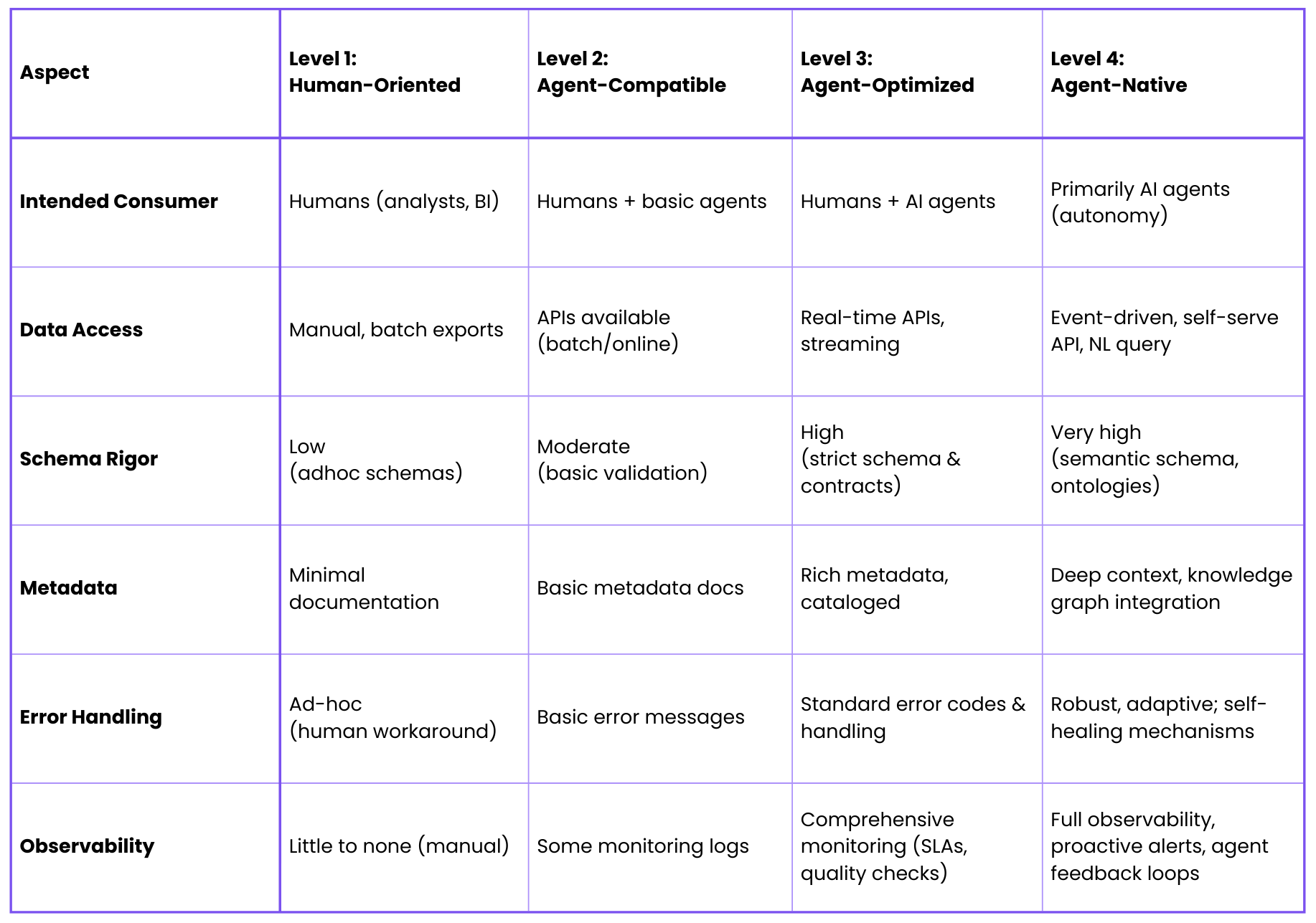
Table 1: Comparison of maturity levels across key aspects.
Each level adds more machine-friendly capabilities across access, schema, metadata, error handling, and observability, as detailed in the next section.
Evaluation Framework: Data Readiness for AI Agents
To evaluate your data product’s maturity and identify improvement areas, I recommend examining five critical dimensions: Access, Schema, Metadata, Error Handling, and Observability. These dimensions cover the technical qualities that make a data product consumable by AI agents. For each dimension, I am providing: key questions to assess, a maturity table to evaluate what each level looks like, and example metrics or tools to guide improvements.
Why these five? Imagine an AI agent trying to use your data product:
It needs to access the data easily.
It must understand the structure (schema) and trust it won’t unexpectedly change.
It benefits from metadata to grasp context.
It relies on predictable error handling since it can’t improvise like a human. Well, for the time-being.
And both you and the agent need observability to ensure everything is working and improve over time.
By scoring each dimension, you can pinpoint which aspects of your data product are holding back agent adoption. Not all systems will progress evenly – for instance, you might have great APIs (Access) but poor metadata. This framework helps isolate such gaps. In practice, all dimensions need to reach a higher maturity to truly unlock agent value; a weakness in even one can undermine the overall readiness.
Let’s dive into each dimension:
1. Access - Data Accessibility and Integration
Definition: Access refers to how easily an AI agent can retrieve and interact with the data product. This covers the interfaces available (APIs, queries, streams), the format of data delivery, and how quickly and conveniently data can be pulled into an AI’s workflow. High maturity in Access means an agent can get the data it needs on-demand, in real-time, with minimal friction.
Key Assessment Questions:
Interfaces: How is the data product accessed? Do you provide a REST/GraphQL API, SDK, or streaming interface, or is it only via manual file download or database queries by humans?
Timeliness: Can data be accessed in real-time or near real-time by an agent, or only in batch windows? (E.g., can an agent query fresh data on the fly?)
Integration: Are there standardized access protocols that typical AI tools can integrate with (HTTP+JSON, SQL, etc.)? Is authentication and authorization designed so that a machine (not just a person) can obtain a token and fetch data?
Self-Service: Can new consumers (or agents) discover and start using the data product’s interface easily, or does each integration require custom work?
Maturity Levels – Access:
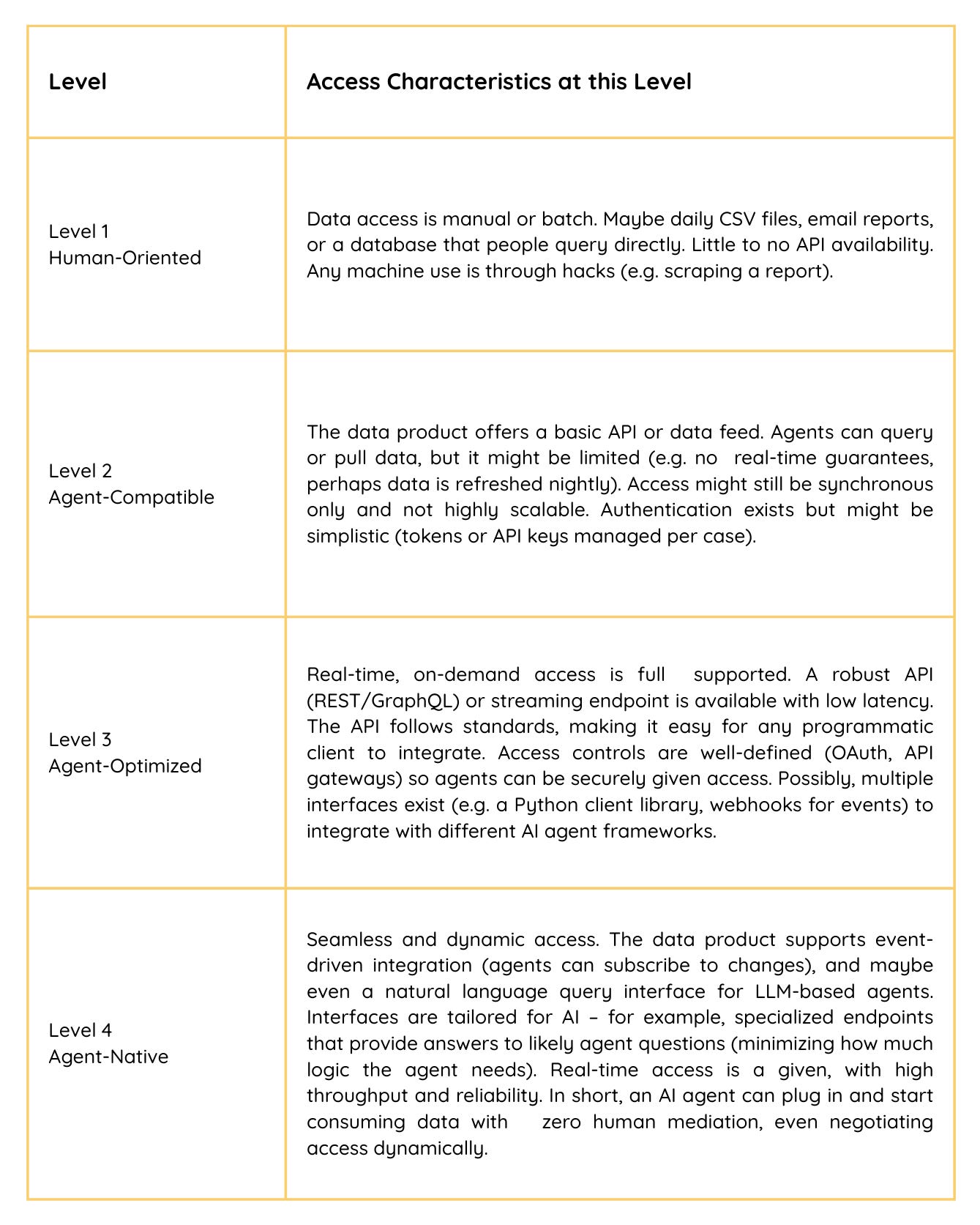
Evaluation metrics and Tools
Aid your evaluation with metrics. You might want to measure API latency (e.g. p95 < 200ms), uptime (≥99.9% SLA), and usage (number of agent calls per day). The presence of standard data connectors or SDKs (e.g. a Python client for your data product) is a sign of high maturity, as it reduces custom effort for each agent integration.
2. Schema - Structure and Data Contracts
Definition: Schema covers the formal structure of the data product – the models, fields, types, and relationships – along with how consistently they are enforced. For an AI agent to consume data without confusion, the data’s structure must be well-defined, stable, and communicated. High schema maturity often involves implementing data contracts (clear agreements on schema and semantics between producers and consumers) and automated validation. I have discussed data contracts in the previous chapter. If you want to dive deep the consumer-defined data contract blog is a good resource.
Key Assessment Questions:
Defined Structure: Is there a clear schema for the data (tables defined, JSON fields specified, etc.)? Or is it semi-structured/free form?
Validation: Do you validate incoming data against the schema to prevent breaking changes or corrupt data? (e.g., type checks, required fields)
Evolution: How are schema changes handled? Do you version your API or dataset schema and communicate updates to consumers? Can an agent discover the schema (like via an OpenAPI spec or GraphQL schema introspection)?
Consistency: Are there enforced data types and constraints (unique IDs, referential integrity)? Is the semantics of each field documented (e.g. “start_date is the date the order was placed”)?
Data Contracts: Have you established data contracts between data producers and the data product consumers that include schema and semantics? (Here is a good blog that dives into the how-to)
Maturity Levels – Schema:
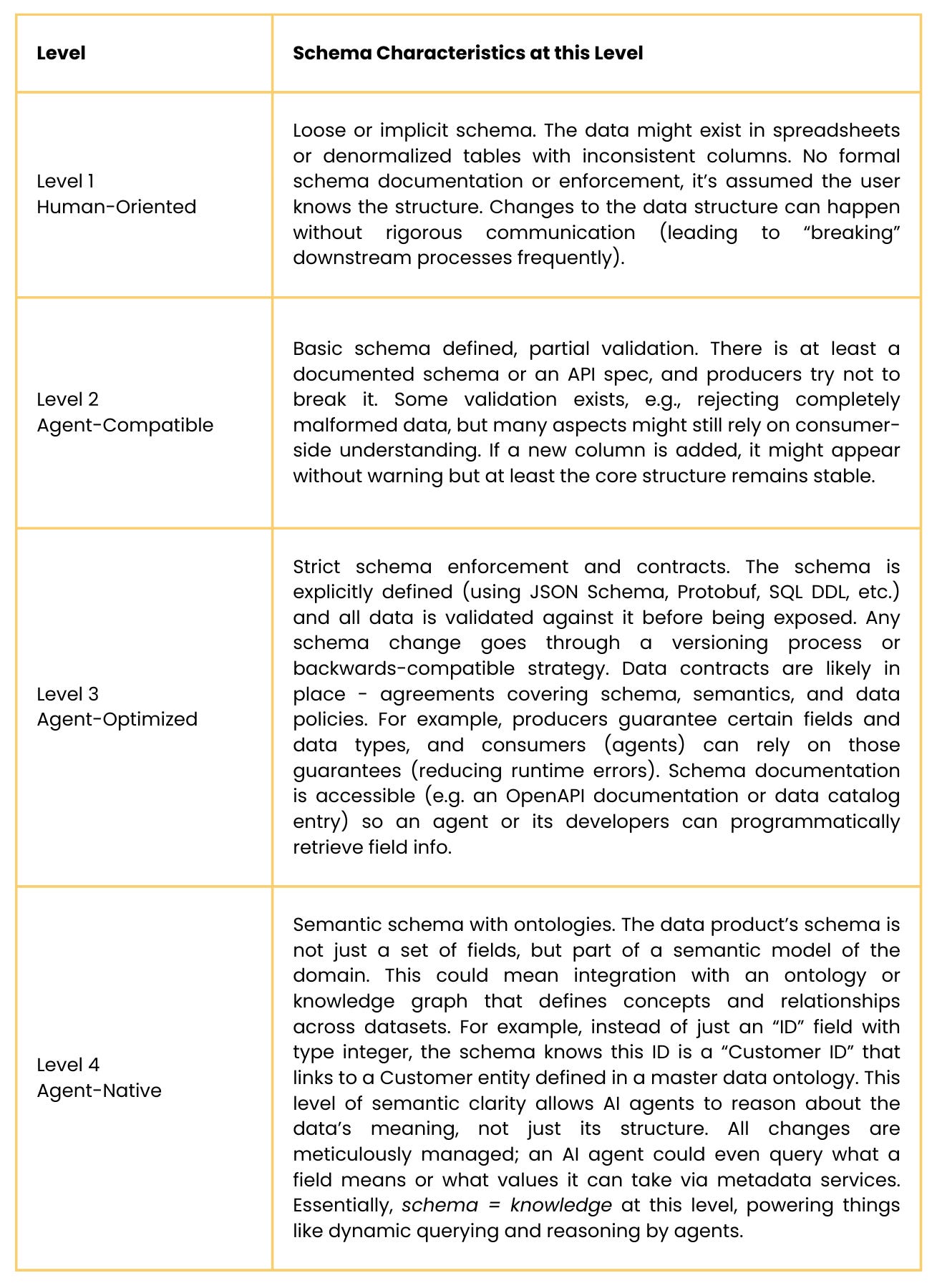
Evaluation metrics and Tools
Use these metrics to evaluate how strict, transparent, and stable your data product schemas are. Metrics might include schema change frequency (and how often those changes caused incidents, ideally zero at high maturity due to good contract management) and validation error counts (number of times bad data was caught by schema checks, indicating protection). COnsider using schema registries (for streaming data, e.g. Glue Schema Registry), OpenAPI/GraphQL schemas for APIs, and data contract testing frameworks. Adopting data contract practices (as championed by Chad Sanderson and others) is a hallmark of reaching Level 3+ because it aligns producers and consumers on expectations.
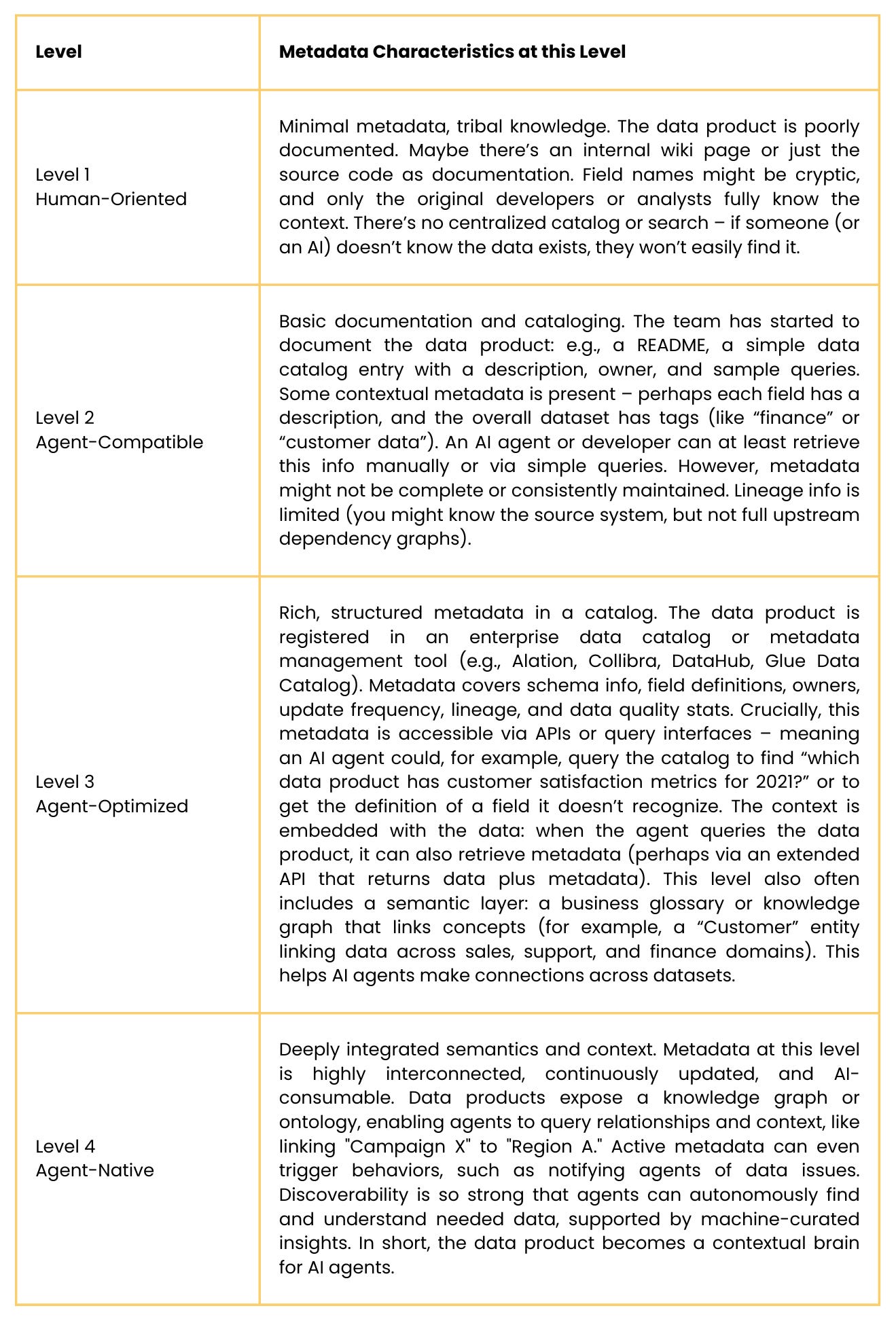
3. Metadata - Discoverability and Semantics
Definition: Metadata is information that describes the data product – its meaning, origin, usage, and context. This dimension ensures that an AI agent (and its human operators) can discover the data product, understand what the data represents, and trust its lineage and quality. High maturity means metadata is rich, actively managed, and accessible in machine-readable forms, providing context that guides correct usage.
Key Assessment Questions:
Discovery: Is the data product easily discoverable? (e.g., listed in a data catalog or registry that agents or developers can query)
Documentation: Do you provide data dictionaries, definitions of fields, example queries or usage scenarios? Are these in a form that could be parsed or retrieved via API (not just a PDF manual)?
Lineage: Does the metadata include lineage (where the data comes from) and timestamps (last updated) so an agent knows how fresh and reliable it is?
Semantic Enrichment: Have you tagged or linked data to business terms or ontologies (e.g., indicating that a column “Region” aligns with a standard list of regions)? Is there a semantic layer that an agent can leverage for more intelligent queries (like knowing how different datasets join or relate)?
Usage Metadata: Do you capture how the data is used, or quality metrics (like distribution, data quality score) that are exposed as metadata? For instance, an AI agent might check “data_quality_score > 0.9” before trusting data for a critical decision.
Maturity Levels – Metadata:
Evaluation metrics and Tools
Rich, up-to-date metadata, embedded with semantic meaning, is essential for agents to correctly interpret data without human clarification. Use metrics to assess the completeness, freshness, and usability of your metadata. A key metric to measure is metadata coverage (e.g., what percentage of fields have descriptions, what fraction of datasets are cataloged). Also metadata freshness (are lineage and documentation updated in real-time with the data?). Use data catalog platforms like (Alation, DataHub, Glue Data Catalog), knowledge graph tools (RDF stores), and metadata APIs. Another metric is searchability – time it takes for a user/agent to find a needed data product (should decrease as maturity increases).
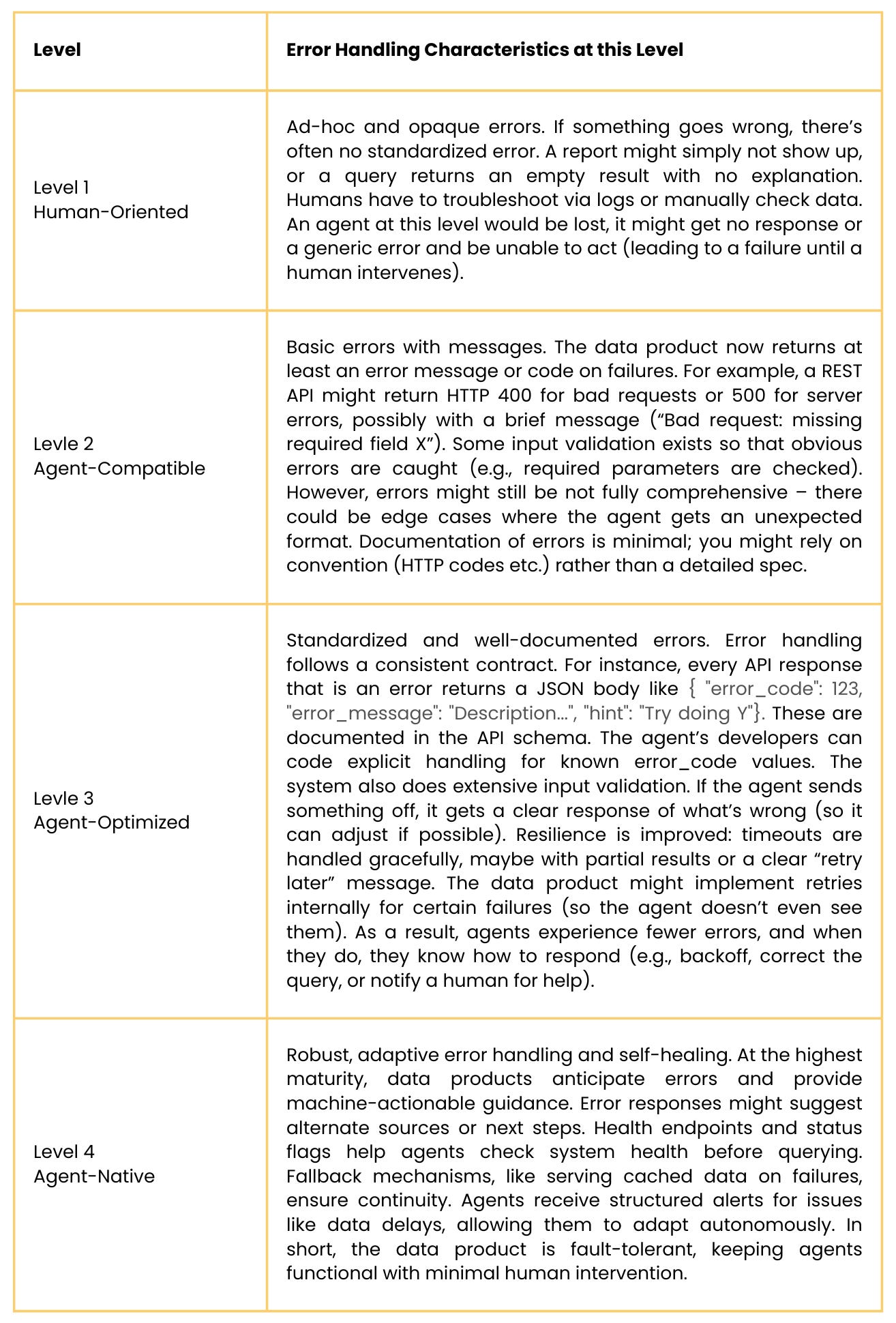
4. Error Handling and Resilience
Definition: Error Handling covers how the data product behaves when something goes wrong or when it receives a bad request. This is crucial for AI agents because unlike humans, agents can’t easily workaround ambiguous errors. They need consistent, clear, and preferably machine-interpretable error feedback. This dimension also includes the resilience of the system – preventing errors where possible, and recovering gracefully when they occur.
Key Assessment Questions:
Error Responses: When an agent makes a request that fails (due to bad input, or server issue), does the data product return a clear error message or code? Or does it just time out or give a generic failure?
Consistency: Are error formats consistent (e.g., always a certain JSON structure with
error_codeandmessage), so that an agent can be coded once to handle errors?Documentation: Are error codes and possible issues documented for integrators? Will an agent (or developer) know what it means if it gets error code 42, and what to do next?
Validation & Prevention: Does the data product validate inputs and provide quick feedback (like telling an agent that its query parameter is invalid rather than just failing silently)? Does it prevent common errors such as SQL injection, wrong data types, etc., that could confuse an agent?
Recovery & Retries: Is the system robust – e.g., can the agent retry if it gets a transient error? Are there built-in retries or failovers on the service side that minimize downtime? Essentially, how fault-tolerant is the data product to upstream outages or data delays?
Maturity Levels – Error Handling:
Evaluation metrics and Tools
Predictable error responses, fallback mechanisms, and structured failure handling are critical for agent autonomy. Use metrics that measure how effectively your data product prevents, communicates, and recovers from errors. You can track error rate (how many requests result in errors, ideally trending down as maturity increases), and MTTR (mean time to recover) for data incidents, high maturity should see automated recovery or fast resolution. Tools that help include API testing and monitoring (ensuring error responses follow the spec), contract testing (e.g., Pact) to enforce error formats, and resilience patterns (circuit breakers, retries via frameworks like Polly or Hystrix). Also, collecting logs of agent interactions to see where they fail can guide improvements. Ultimately, reducing the need for human firefighting when errors occur is the goal, instead of waking up an engineer at 2am, the agent and data product should handle many issues by design.
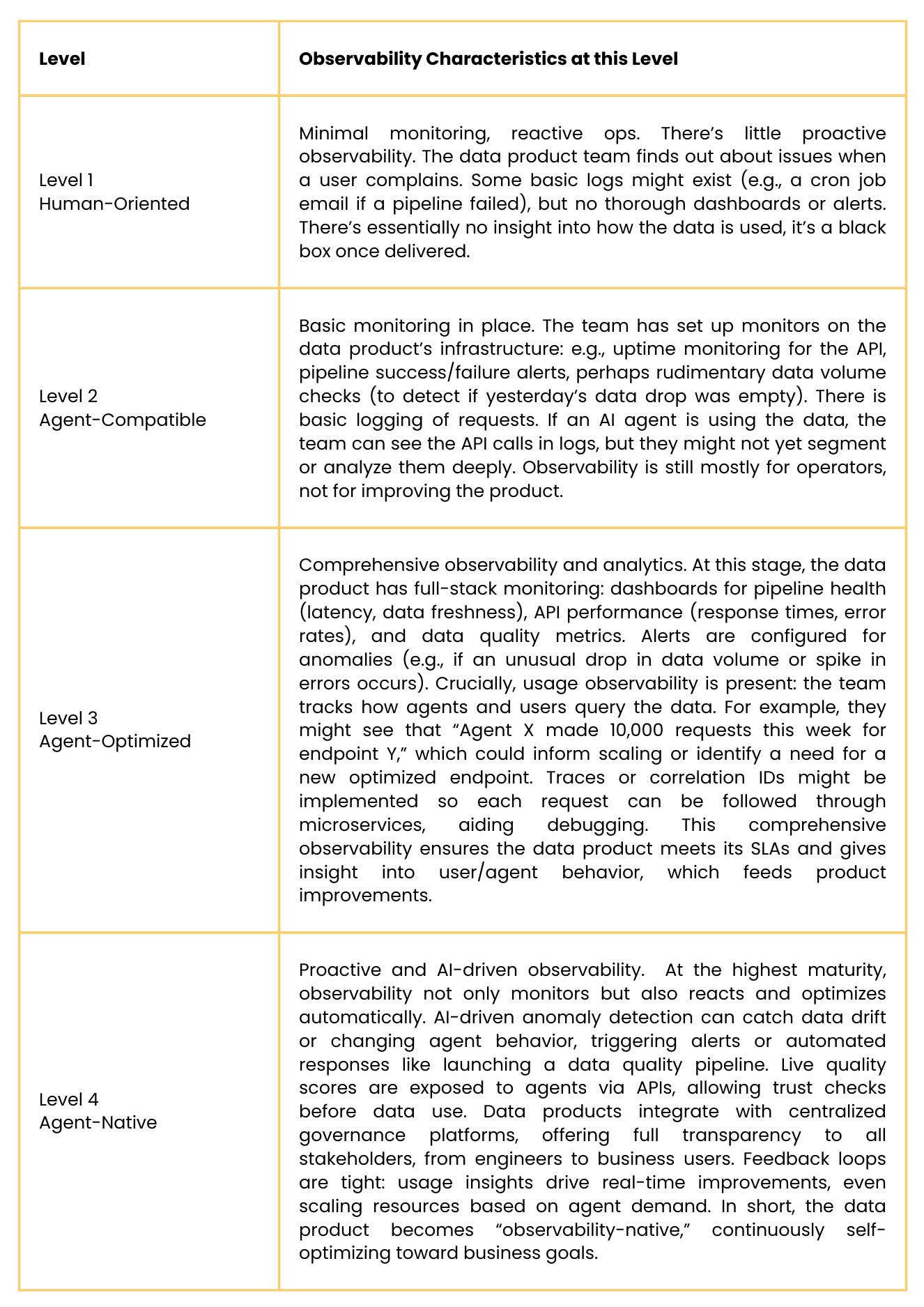
5. Observability and Monitoring
Definition: Observability means having the instrumentation and monitoring in place to understand how the data product is behaving and being used. For agent-ready data products, observability serves two purposes: (1) Operational monitoring – so data engineers and SREs can ensure the system is healthy and meets SLAs; and (2) Usage analytics – so product owners can see how AI agents are using the data (which queries, what frequency, any unusual patterns) and feed that back into improvements. In high maturity, observability might also feed into the AI agents themselves, enabling adaptive behaviors.
Key Assessment Questions:
Monitoring: Do you monitor the data pipeline and APIs for performance (latency, throughput) and errors? Are there alerts when something is slow or broken?
Data Quality and Freshness Checks: Are there automated checks for data quality issues (e.g., volume anomalies, schema drift) that are reported? Can consumers (or agents) access those quality metrics or freshness indicators?
Usage Tracking: Do you track how often and by whom (which agents or apps) the data product is accessed? E.g., query logs, popular queries, user/agent behavior.
Traceability: Can you trace a request from an agent all the way through to the source data and back? This might involve correlation IDs or logs that tie an agent’s query to the data product’s internal processes, helpful for debugging and auditing.
Feedback Loops: Is there a mechanism for capturing feedback or issues from consumers? For example, if an AI agent frequently queries something it shouldn’t or gets wrong answers, do you capture that somehow (maybe via user feedback on the agent) and feed it back to improve the data or metadata?
Maturity Levels – Observability:
Evaluation metrics and Tools
Mature observability also powers feedback loops that allow agents to adapt based on real-time signals. These metrics assess how well you instrument and track both system health and agent interaction patterns. Common technical metrics are uptime, throughput (requests per second), latency, data freshness lag, and data quality indicators (like percentage of records passing all quality checks). Business/usage metrics might include number of active consuming agents/users, query frequency, and maybe coverage (e.g., what fraction of the data is actually being used by the AI, to identify unused data). Use observability tools like OpenSearch, Prometheus, Grafana; data observability tools like Monte Carlo, Great Expectations for data quality checks. Logging and distributed tracing (using OpenTelemetry, for example) are important to tie it all together. At high maturity, consider anomaly detection on metrics (using ML to spot issues humans might miss) and automated runbooks that trigger when certain alerts fire.
What’s next?
I'll pause the blog here. The next chapter will dive into a prescriptive roadmap, covering implementation steps, team and organizational structures, and a hands-on maturity scoring rubric you can use.
For now, take some time to digest the evaluation framework.
Think about:
How you might set up time for a real evaluation?
Who the key stakeholders in your organization should be?
How to prepare for effective stakeholder interviews? Because evaluation is part science, part art.
If you spot opportunities for improvement, have ideas, or want to challenge any part of this framework, I would love to hear from you. Comment, message me, reach out, this space is evolving fast, and thoughtful challenges only make it better.
Stay tuned. The practical roadmap is coming next!