
Chapter 4: Improve your data maturity for Agentic AI
Implementation roadmap for building Agent-Native data products.

Introduction
This blog series has been an eye-opener for me. My continous research on this topic has led me to so many ideas in this space. I am also finding signals that are quite validating of the future of data products. Model builders are increasingly solving the integration issues (MCP, A2A), that frees up more time for enteprises to focus on data - building the data assets for the agents. I am writing this blog series with two things in mind - a) how do we present data to AI agents at scale, b) how do enteprises can get started.
Chapter 3 (previous) and this one focuses on the getting started piece. In Chapter 3, I covered the maturity model of data products for AI agents and provided a framework to assess maturity. This is important, as it gives you a picture of Point A - your current state and your starting point.
In this chapter, I am sharing how you can start climbing the maturity curve, from Point A to Point B (where you want to be).
Note: I have used names of tools in different sections. These are just examples, choice of tools will depend on a number of factors in your business.
Implementation Roadmap
Achieving Agent-Native data products is a journey. I am outlining a four-phase implementation roadmap - each phase builds capabilities and deliverables that correspond roughly to improving through the maturity levels. The phases are: Foundation, Standardization, Optimization, and Innovation.
Technical leaders can use these as guideposts to plan and sequence their transformation.
Phase 1: Foundation
Focus: Establish the basics. Begin treating data as a product, not a one-off project. This is about moving from ad hoc delivery to consistent, managed data services.
Key Initiatives & Deliverables:
Identify & Prioritize Data Products: Select high-impact datasets that are relevant to current or future AI initiatives. For example, prioritize customer profiles, inventory feeds, or order history APIs that support automation use cases. Assign data product owners and consumers. Many organizations choose strategic use cases with top-down sponsorship and budget.
Basic API Access: Create simple APIs to expose data that's currently only available in reports or databases. Like, stand up a REST API for customer transactions that internal applications can use today and agents can use later.
Initial Documentation: Document each product with its purpose, consumers, update frequency, and owner. Use tools like Notion, Confluence, or your data catalog. Even a well-maintained Google Doc is better than tribal knowledge.
Schema Definition: Write down the schema in JSON, YAML, or SQL. Start enforcing it in pipelines using tools like Great Expectations or dbt tests to catch missing or malformed fields.
Basic Monitoring: Add simple pipeline success/failure checks. For example, email alerts when a batch job fails or basic uptime monitoring via a status page.
Outcome: A few well-scoped data products with API access, schema enforcement, monitoring, and ownership. You've reached Agent-Compatible maturity for these products.
Phase 2: Standardization
Focus: Establish shared practices and governance. Scale with consistency. Move from DIY builds to factory-grade repeatability.
Key Initiatives & Deliverables:
Standard APIs & Data Contracts: Create internal guidelines for versioning, naming, error handling, and SLAs. For example, enforce
/v1/,/v2/API paths, and define consistent HTTP error codes. Share a contract template covering schema rules and SLAs.Data Catalog & Glossary: Populate a central catalog like Alation, DataHub, or Amazon DataZone catalog with all products. Define business terms and link them to data fields. Assign owners to glossary terms. For instance, link "customer_type" in your marketing dataset to the enterprise-wide definition in the glossary.
Data Quality & Schema Governance: Schedule daily validation jobs for critical datasets using Great Expectations or similar tools. Review breaking schema changes through a Slack approval workflow or GitHub PR process.
Access Controls: Integrate APIs with your identity provider (e.g., Okta or Amazon Cognito). Use API gateways like Kong or Apigee to enforce tokens and rate limits.
Central Monitoring: Create reusable dashboards using CloudWatch, OpenSearch, Datadog or Grafana templates. Include metrics like latency, error rate, and volume. Review these weekly during ops check-ins.
Outcome: Data products are consistent and governed. You now have guardrails, templates, and SLAs to support new products with minimal overhead. You're progressing into Agent-Optimized maturity.
Phase 3: Optimization
Focus: Improve performance, support real-time needs, and integrate agents. This phase makes your platform efficient and AI-adaptive.
Key Initiatives & Deliverables:
Enable Real-Time Flows: Move from batch to streaming where needed. Use Kafka or CDC to stream updates. For example, convert a daily product inventory batch job into a Kafka stream that emits update transactions every time stock changes.
Improve Latency & Throughput: Profile data pipelines. Add Redis caching for read-heavy APIs or migrate to columnar databases like ClickHouse. Define and track latency SLAs.
Advanced Error Handling: Standardize error responses across all APIs. Add hints to error payloads (e.g., “suggested_action” fields). Create a public error catalog documenting error codes, meanings, and remediation steps.
Observability Upgrade: Implement distributed tracing using OpenTelemetry. Introduce anomaly detection for freshness or volume drops. Send alerts to Slack or any other system with push notifications.
Pilot Agent Integration: Build a real AI agent that consumes your data product. For instance, a chatbot using the API to answer customer queries about inventory. Log interactions and note recurring issues (e.g., missing metadata or ambiguous fields).
Feedback Loops: Log agent requests and measure how often they result in errors, missing data, or unexpected results. Use this to prioritize roadmap improvements.
Outcome: Your data products support intelligent, real-time interaction. You've achieved Agent-Optimized maturity across multiple dimensions.
Phase 4: Innovation
Focus: Enable adaptive, self-optimizing, AI-native data products. This phase positions your platform to scale autonomous workflows confidently.
Key Initiatives & Deliverables:
Semantic Layer & Knowledge Graphs: Expose business concepts as a graph. For example, a knowledge graph linking customers, products, and campaigns allows an agent to answer: “Which customers in Europe bought Product X during Campaign Y?”
Agent-Specific Interfaces: Create higher-level APIs or LLM-facing endpoints that wrap complex queries. For example, build an endpoint like
/get_insights?question=...that lets agents ask questions in natural language.Self-optimizing Systems: Use tools like Amazon DevOps Guru or custom logic to scale infrastructure based on agent demand. Automatically archive cold data or recommend schema changes based on usage trends.
Governance Automation: Deploy AI tools for compliance tracking and PII detection (e.g., BigID, Immuta). Generate monthly compliance reports automatically.
Organization-wide AI Integration: Build internal docs and SDKs that help other teams integrate with your data platform. For example, a Python package that wraps common agent-data queries.
Innovation Experiments: Pilot new capabilities like vector search, natural language APIs, or real-time graph queries. Not every experiment will succeed, but they ensure your platform evolves.
Outcome: Your data products are now Agent-Native. They support autonomous agents by design, adapt intelligently, and are deeply integrated with the organization's AI fabric. You likely have a platform that can answer complex, cross-domain questions by virtue of the semantic layer and knowledge graphs. Measuring success becomes the next focus.
Team Roles, Organization, and Governance at each Maturity Level
Evolving through the maturity levels isn’t just a tech challenge, it’s also organizational. Different roles, team structures, and governance processes are needed as you progress:
Level 1 (Human-Oriented)
Minimal Roles & Ad-hoc Governance: Early on, there might not even be a concept of a “data product team.” The work could be done by a lone data engineer or a BI analyst who produces data outputs on request.
Roles: No dedicated data product owner; the “owner” might be an IT manager or the analyst themselves.
Team Structure: Very centralized or single-threaded – one team might manage all data assets in a siloed way.
Governance: Largely ad-hoc. There may be basic security rules, but no formal data governance board or standards. Essentially, people rely on personal communication (“Hey, is this data up to date?”) to manage usage.Level 2 (Agent-Compatible)
Introduction of Data Product Owner and Team: As you start treating data as a product, it becomes crucial to assign clear ownership.
Roles: A Data Product Owner/Manager - someone responsible for understanding consumer needs (including AI agents’ needs) and prioritizing features (like API access, documentation). Data Engineers and possibly a Data Analyst or Scientist form a small Data Product Team to build and maintain the product.
Team Structure: Could still be centralized (a single team managing multiple products) but adopting product management practices. Alternatively, you might align teams to domains (e.g., a Sales data product team).
Governance: At this stage, you likely form a data governance working group or at least set some standards - for example, deciding that all data products must have an assigned owner and must comply with certain API standards. Governance is light but building - perhaps periodic meetings to review data quality issues or access requests.Level 3 (Agent-Optimized)
Cross-Functional Teams and Platform Support:
When optimizing for agents, the complexity often requires a cross-functional approach.
Roles: In addition to Data Product Manager and Data Engineers, you may need ML Engineers or AI Specialists embedded to ensure the data product works well with AI (for example, helping create embeddings or integrating with an LLM). If real-time and reliability are goals, a Site Reliability Engineer (SRE) or Data Ops role might be added to the team to handle observability and performance. We also see the rise of a Data Platform Team – a central team that provides common tooling (catalog, pipeline frameworks, CI/CD, monitoring) for all data product teams.
Team Structure: Often follows a hub-and-spoke model: domain-aligned data product teams (spokes) that own their products end-to-end (from ingestion to API), supported by a central data platform (hub) that gives them self-service tools. Each data product team at this stage acts almost like a mini startup – building, versioning, and iterating their product, with the Data Product Owner liaising with consumers (including internal AI teams).
Governance: Formal governance kicks in. A Data Governance Board or Council might be established, including data owners, architects, and possibly the CDO (Chief Data Officer). This body sets enterprise-wide policies – e.g., how to handle PII, standards for metadata, approval for new data products – but execution is federated to the teams. The governance also ensures compliance and that every data product meets the minimum requirements of quality and documentation. Automated governance tools might be introduced to support this.Level 4 (Agent-Native)
Advanced Roles and Federated Organization: At full maturity, data products and AI are deeply intertwined, which may give rise to new specialized roles.
Roles: One might see a Knowledge Engineer or Ontology Specialist who manages the knowledge graph and ensures semantic consistency across products. There could be Prompt Engineers or AI Ops roles working with data teams to build those agent-specific interfaces and monitor agent performance. Also, Data Stewards become important – these are domain experts who ensure the data in their domain is correct and used properly; they work closely with data product teams to define metrics and business rules.
Team Structure: Likely a federated model like Data Mesh: each domain (marketing, finance, etc.) has its own data product teams responsible for their data as products, and there is a central enabling team (could be an evolution of the data platform team) that provides governance, standards, and maybe some shared services like the knowledge graph infrastructure. This enabling team might also run a Center of Excellence for AI integration, helping each domain figure out how to expose their data to AI agents effectively. In essence, the organization becomes networked: domain teams owning data, a platform team enabling tech, and a governance council ensuring alignment – all working in concert.
Governance: At Level 4, governance is both centralized and automated. Policies (like access control, PII handling) are enforced via the platform (control plane governance) across all data products. The governance council continuously measures each data product’s maturity and value. Data products might even be audited for AI readiness – e.g., a checklist or scoring is regularly evaluated. There’s a strong culture of treating data as a strategic asset, and governance is seen as a shared responsibility rather than a bureaucratic hurdle.
To summarize the org evolution: early on, people wear multiple hats and processes are informal. By mid-maturity, dedicated roles and repeatable processes emerge (e.g., a designated product owner, standard devops for data). At full maturity, specialists and a federated structure ensure both domain-specific knowledge and enterprise-wide consistency. It’s important to manage this change: investing in training and clear role definitions will pay off. Many organizations create playbooks for “what is expected of a data product owner” or “how the platform team engages with domain teams” to avoid confusion.
My advise is don’t underestimate the cultural shift. Getting to Agent-Native maturity will need convincing stakeholders to let go of some control (for instance, domain teams must trust the central platform for governance automation, and central teams must empower domains to design products freely within guidelines). Leadership buy-in is crucial to drive this organizational maturity alongside the technical maturity.
Self-Assessment: Maturity Scoring Rubric
How do you know where you stand and what to tackle next? A maturity self-assessment can be done using a simple scoring rubric across the five dimensions we discussed. For each dimension, evaluate which level best describes your current state. The matrix below (Table 2) summarizes the criteria for each dimension at each maturity level:
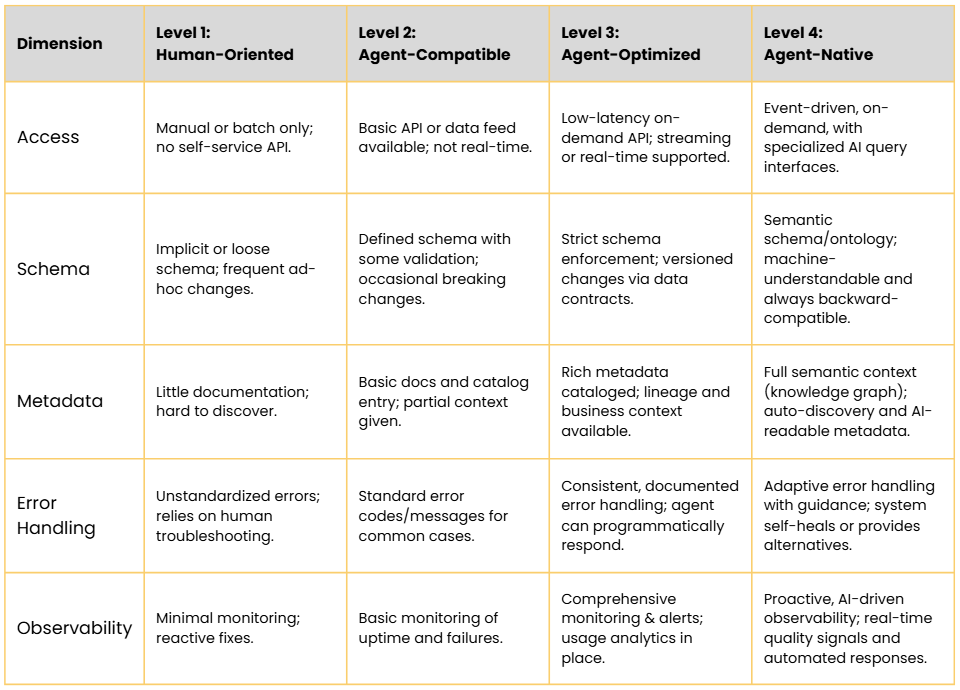
Table 2: Agent-Ready Data Product Maturity Rubric. Use this to score each dimension from 1 to 4. A truly agent-ready (Level 4) data product would score 4’s across the board. More likely, you’ll see a mix – which is fine, it highlights areas for improvement.
How to use this rubric: For each dimension, if you mostly match Level 2 with a couple aspects of Level 3, you might score yourself a 2 or 2.5. It doesn’t need to be exact, the goal is to provoke discussion and planning. If certain rows are much lower than others (say, Observability is lagging while Schema is advanced), that’s a sign to balance your efforts. It’s often useful to involve a few people (data engineers, product owners, even a consumer or two) in the scoring to get a 360-degree view.
After scoring, you can prioritize which improvements will elevate the lower scores. Use assessment framework from earlier sections: which questions to address, which roadmap phase tasks to focus on. Over time, you can re-score to track progress. Some organizations even make this a quarterly ritual, to ensure continuous improvement in data maturity.
Measuring Success: Metrics that work
Improving data product maturity is not an end in itself, it should translate into better outcomes for both technology and business. As you implement the Agent-Ready Data Product Maturity Model, consider how you will measure success.
I recommend tracking metrics in three categories: technical metrics, agent (AI) metrics, and business metrics.
1. Technical Metrics
These metrics mainly measure quality and performance of data products.
Data Quality Index: A composite score of data accuracy, completeness, consistency (e.g., percent of records passing all quality checks).
API Performance: Average and p95 latency of data API responses; API uptime/downtime; error rate (percentage of calls that result in errors).
Freshness/Staleness: How old is the data when delivered? E.g., 99% of data is updated within X minutes of source change.
Schema Change Frequency: How often does the schema evolve, and how often does it cause an incident? Ideally, high maturity has fewer breaking changes; changes are compatible or communicated.
Observability Coverage: e.g., percentage of critical metrics that have alerts, or ratio of issues detected via monitoring vs reported by users (you want more detected by monitoring over time).
These technical metrics ensure the infrastructure and data quality are meeting the needs. For instance, if API latency is too high, an AI agent might time out or be unable to provide real-time answers, hurting adoption. Tracking improvements in these metrics (like latency dropping after Phase 3 optimizations, or data quality scores rising after implementing contracts) provides concrete evidence of progress. Also, remember that poor data can be costly – Gartner estimates that poor data quality costs businesses on average $12.9 million per year, so improving these technical metrics has direct financial impact beyond agentic needs.
2. Agent Metrics:
These metrics look at how AI agents are interacting with the data product and how well that’s going.
Agent Adoption: Number of AI agents or applications actively using the data product. (e.g., “3 chatbots and 2 recommendation systems pull from this product each week”).
Agent Query Volume: How many queries or data fetches by agents per period?Growth in this indicates the data product is increasingly useful to AI.
Agent Success Rate: If applicable, measure the success rate of agent tasks that depend on the data. For example, if an agent answers user questions using the data product, what percentage are answered confidently and correctly? Or if an agent tries to execute a workflow using the data, how often does it complete without human intervention?
Error Interaction Rate: How often do agents encounter errors or need to retry? (This ties with technical error rate, but specifically focusing on agent-facing incidents). As maturity improves, this should decrease.
Integration Effort: A more subjective metric. How much effort does it take to integrate a new agent with the data product? Could be measured via a survey or hours of work. At high maturity, integrating a new AI agent should be plug-and-play, whereas at low maturity it might require custom coding and troubleshooting.
Agent metrics basically measure how “friendly” and useful your data product is to the AI agent. If you increase agent adoption and they are succeeding, it’s a strong sign your maturity improvements are working. For example, if after adding a semantic layer, you see agents can answer far more complex queries (success rate up) or new agents onboard quicker, that’s tangible success. If agent query volume is stagnant, perhaps the data product isn’t delivering what they need or the AI teams don’t trust it – an indicator to investigate.
3. Business Metrics:
Ultimately, all this should translate into business value. These metrics can be specific to your use cases, but some examples:
Decision Speed: How fast can certain decisions be made now that AI agents have data? For example, “time to generate monthly report reduced from 3 days (manually) to 1 hour (AI agent)” - this measures agility gains.
Cost Savings: Reduction in operational cost due to automation or improved data quality. For instance, fewer manual data preparation hours (because agents fetch data themselves), or less revenue loss from errors (because data is accurate). You can quantify hours saved or incidents avoided.
Revenue or Opportunities Enabled: If the matured data product enables new AI-driven initiatives, did they produce new revenue or customer value? e.g., launching a personalized AI-driven recommendation feature increased cross-sell revenue by X%.
User Satisfaction: If the data product serves internal users (e.g., an analyst or a business user consuming through an AI assistant), measure their satisfaction. Maybe via surveys (“Data is easier to find/use now”) or NPS scores for your data platform.
Compliance and Risk Metrics: Though less exciting, an important business metric is risk reduction. E.g., number of compliance incidents related to data usage (should drop as governance matures). Or audit findings - “no critical findings in latest data audit” can be a huge success metric in regulated industries.
I recommend tying improvements to these business metrics whenever possible. For example, if after Phase 2 (Standardization) you see a drop in manual data prep work for the analytics team by 50%, highlight that. If Phase 3’s real-time pipeline allowed an AI to make decisions that saved $100K in logistics costs by reacting faster to supply chain changes, capture that story. Business leaders will be motivated to continue investing when they see these outcomes. It also helps to set some target metrics at the start of your journey (like “reduce manual data requests by 80% in 1 year” or “enable at least 3 AI use cases with this data in 6 months”) and track against them.
Summary
Adopting any maturity model is a transformative effort. It requires technology upgrades, process changes, and cultural shifts. By following the structured model (Levels 1–4), evaluating your progress with the five-dimension framework, and iteratively implementing improvements through the roadmap, you can methodically advance your organization’s capabilities. The payoff is significant: data products that not only serve your analysts, but also power AI-driven automation and insights at scale. In a time where AI promises competitive advantage, having truly agent-ready data is the foundation to realize that promise.
Remember that this is a journey - celebrate incremental wins. Maybe your first achievement is simply getting an API running (moving from Level 1 to 2 in Access), or cataloging a dataset so people can find it. Each step brings you closer to data products that are AI-ready by design. Engage your team with this vision, use the rubric to track progress, and continuously refine based on feedback (both from humans and AI agents!). Over time, you’ll find that not only are your AI agents happier, but your human data consumers are too – because many of the improvements (better documentation, quality, faster data) benefit everyone.
In the end, an agent-ready data foundation means AI can truly become a reliable teammate in your enterprise, driving smarter decisions and automating routine analysis, all on trustworthy data products.
What next?
Most data-maturity initiatives fail because they don’t deliver measurable ROI. I worry the same will happen as you begin transforming your data assets for AI agents: while promising, AI agents’ ROI hasn’t yet been demonstrated at scale, nor have the underlying data products. To address this, I plan to write a chapter on how to capture and measure the ROI of mature data products - not only for agentic AI, but for any business initiative.
Stay tuned!