
Anthropic Adds Skills to Agents - Why Does it Matter?
Anthropic’s Claude now supports Skills - reusable bundles of expertise that make AI smarter at your company’s workflows. Plus: a deep dive into how AI remembers and a hands-on challenge to build.

Hey AgentBuilders,
Thank you for reading this edition.
Today we cover:
BIG NEWS: Anthropic launches Claude Skills - what they are, how they work, and why they matter.
How AI Remembers: A simple visual guide to AI memory and Retrieval-Augmented Generation (RAG).
Weekly Challenge: Build your own long-term memory system with just two Python scripts.
Evolving This Newsletter: How your feedback will shape our shared learning journey.

BIG NEWS: Anthropic launches Claude Skills
What Skills Actually Are:
Skills are folders containing instructions, scripts, and resources that Claude can load when needed for specific tasks. They instill Claude with specific knowledge that it may not possess in its training data.
Claude Skills are like hiring a specialist for specific jobs. Instead of explaining the same process to Claude every single time - how your company formats reports, your brand guidelines, how you analyze sales data - you package those instructions once into a “Skill.” Then Claude automatically uses that expertise whenever it’s relevant.
How They Actually Work:
Claude scans available skills to find relevant matches, and when one matches, it loads only the minimal information and files needed.
When asked to carry out a relevant task, Claude launches the appropriate skill by invoking the Bash tool to read the SKILL.md file.
Skills are composable - they stack together, and Claude automatically identifies which skills are needed and coordinates their use.
Where to Access Them:
Available in Claude apps, Claude Code, and the API.
For Team and Enterprise users, admins must first enable Skills organization-wide in Settings.
Users can add Skills to Claude Code via plugins from the anthropics/skills marketplace.
Pre-built Skills Available:
Anthropic has created skills for reading and generating professional Excel spreadsheets with formulas, PowerPoint presentations, Word documents, and fillable PDFs.

Custom Skills:
The “skill-creator” skill provides interactive guidance - Claude asks about your workflow, generates the folder structure, formats the SKILL.md file, and bundles the resources you need.
Skills require the Code Execution Tool beta, which provides the secure environment they need to run.
Bottom line: This is a developer/power-user feature focused on creating reusable bundles of expertise, not a simple dropdown menu like I originally described in the article.
Read Anthropic Annoucement - Introducing Agent Skills
This week we discussed Agent Memory in AgentBuild Circles
How AI Remembers: A Visual Guide
Ever wonder how AI assistants remember your preferences and past conversations? This diagram reveals the two-step process.
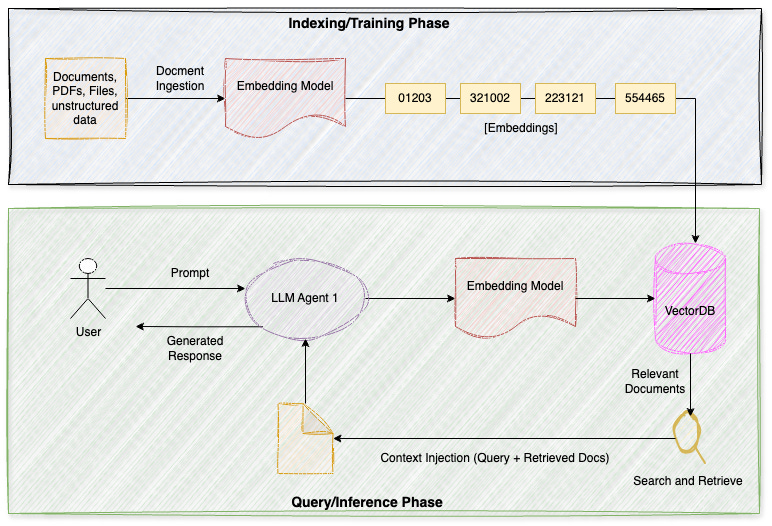
Step 1: Building the Memory Bank (Indexing/Training)
Your documents, emails, and files are broken into chunks, then converted into numerical codes called “embeddings” (those number sequences like 01203, 321002...). Think of it as translating human language into a format computers can search lightning-fast. These get stored in a VectorDB - a specialized database designed for finding similar information.
Step 2: Remembering When You Need It (Query/Inference)
When you ask a question, the magic happens:
Your question gets converted into the same numerical format (embeddings)
The system searches the database (magnifying glass icon) for relevant memories
Retrieved information combines with your question in “Context Injection”- like briefing the AI before it responds
The AI generates an answer informed by both your question and its memories about you
Why It Matters
This architecture - called Retrieval Augmented Generation (RAG) - solves LLM’s biggest limitation: forgetting everything between conversations. Instead of starting from scratch each time, the LLM can instantly access thousands of past interactions, learned preferences, and contextual details.
The result is what you need - AI that knows what you prefer, remembers your project deadlines, and recalls that meeting from last Tuesday. This transforms generic chatbots into genuinely personalized assistants that get smarter with every interaction.
👉 Want to dive deeper, respond DIVE DEEP-RAG to this email. I will schedule a live webinar talking about this pattern and answering your questions.
Weekly Challenge: Simulate long-term memory with these simple Python scripts
Goal
Create a tiny memory system that:
Ingests PDF into a long-term (vector) store
Recalls relevant information from the PDF across sessions to answer new queries
What you need to do
Run the two scripts below.
Create a dummy PDF using an AI Assistant (or use your PDF file - don’t ingest sensitive data)
Ask 5+ queries over at least 2 sessions (separate runs).
Implement one enhancement and share results.
# Script to ingest PDF
import os
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv() #Save your LLM API KEY in the .env file
# 1. Load your local PDF
loader = PyPDFLoader(”startup_demo/<YOUR-FILE>.pdf”)
documents = loader.load()
# 2. Split into chunks for embedding
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
docs = text_splitter.split_documents(documents)
# 3. Create embeddings and vectorstore
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(docs, embeddings)
# 4. Save to disk
db.save_local(”memory/”)
print(”PDF ingested and saved to memory/”)💡 TIP: Paste the code snippets in ChatGPT/Claude/Gemini and ask it to explain each line step-by-step. You will learn what happens through each line of the code.
Try to connect that to the visual I pasted above.
# Script to Query PDF
import os
from crewai import Agent, Task, Crew, Process
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain.memory import VectorStoreRetrieverMemory
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv() #Save your LLM API KEY in the .env file
# Load the stored FAISS vector memory
embedding_model = OpenAIEmbeddings()
db = FAISS.load_local(”memory/”, embedding_model, allow_dangerous_deserialization=True)
# Create retriever-backed memory
memory = VectorStoreRetrieverMemory(retriever=db.as_retriever(search_kwargs={”k”: 3}))
# Setup an agent to answer questions based on PDF
pdf_agent = Agent(
role=”PDF Memory Expert”,
goal=”Answer questions based on the ingested PDF document”,
backstory=”You have read and remembered the entire PDF and can answer questions about it in detail.”,
memory=memory,
verbose=True
)
# Task to ask a question
question = “What are the Strategies and Best Practices for Ensuring Data Quality in AI? Summmarize the section directly from the document”
task = Task(
description=f”Answer this question using your memory: {question}”,
expected_output=”A detailed answer citing relevant parts of the PDF.”,
agent=pdf_agent
)
# Setup crew
crew = Crew(
agents=[pdf_agent],
tasks=[task],
process=Process.sequential
)
# Run
result = crew.kickoff()
print(”\nAnswer from PDF Agent:\n”)
print(result)👉 What to submit (copy/paste this in replies)
What you built (2–3 lines)
A tricky query and what the agent recalled
1 enhancement you added (and how you measured impact)
Evolving the Newsletter
This newsletter is more than updates - it is our shared notebook. I want it to reflect what you find most valuable: insights, playbooks, diagrams, or maybe even member spotlights.
👉 Drop me a note, comment, or share your suggestion anytime.
Your feedback will shape how this evolves.
Found this useful? Ask your friends to join.
We have so much planned for the community - can’t wait to share more soon.
Regarding the article, great clarity. Skills are key for composable agenst.