
DataOps 2.0 Development Phase - Save the Data Engineer from boring, manual tasks
Automating the development phase of DataOps using AI Agents, learn what you need to achieve this, and find out why is it more complex than it looks?

Modern DataOps has made significant strides in orchestration and production monitoring, but the development phase, the bridge between design and production, still heavily relies on human effort. Manual schema adjustments, missing tests, subjective PR reviews, and inconsistent code quality create friction and slow delivery.
This post expands on an idea for embedding agentic intelligence into the development phase of DataOps, with deeper insights into tool usage, LLM-based agent examples, detailed agent interactions, and concrete integration methods.
Step back: Check the Design Phase workflow.
The Development-Time Workflow: Problems and Opportunities
Current issues:
Schema changes require manual edits to
schema.ymland tests.Code reviews are bottlenecks, varying in quality.
Tests are often insufficient or missing entirely.
Organizational coding standards are inconsistently applied.
Agentic Opportunity: Multi-agent workflows can proactively:
Detect and synthesize schema changes.
Enhance and standardize test coverage.
Perform structured, automated PR reviews.
Provide intelligent, context-rich feedback to developers.
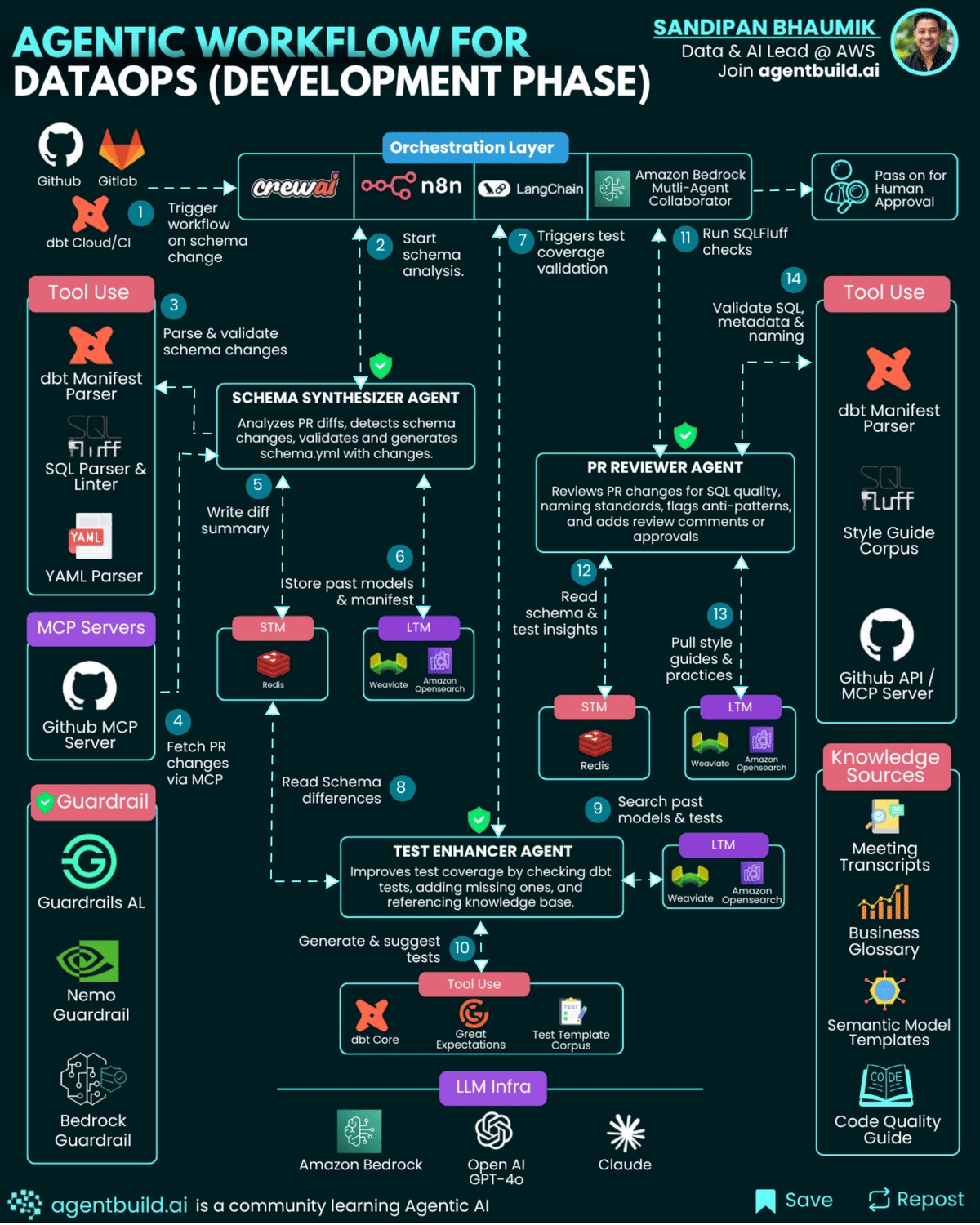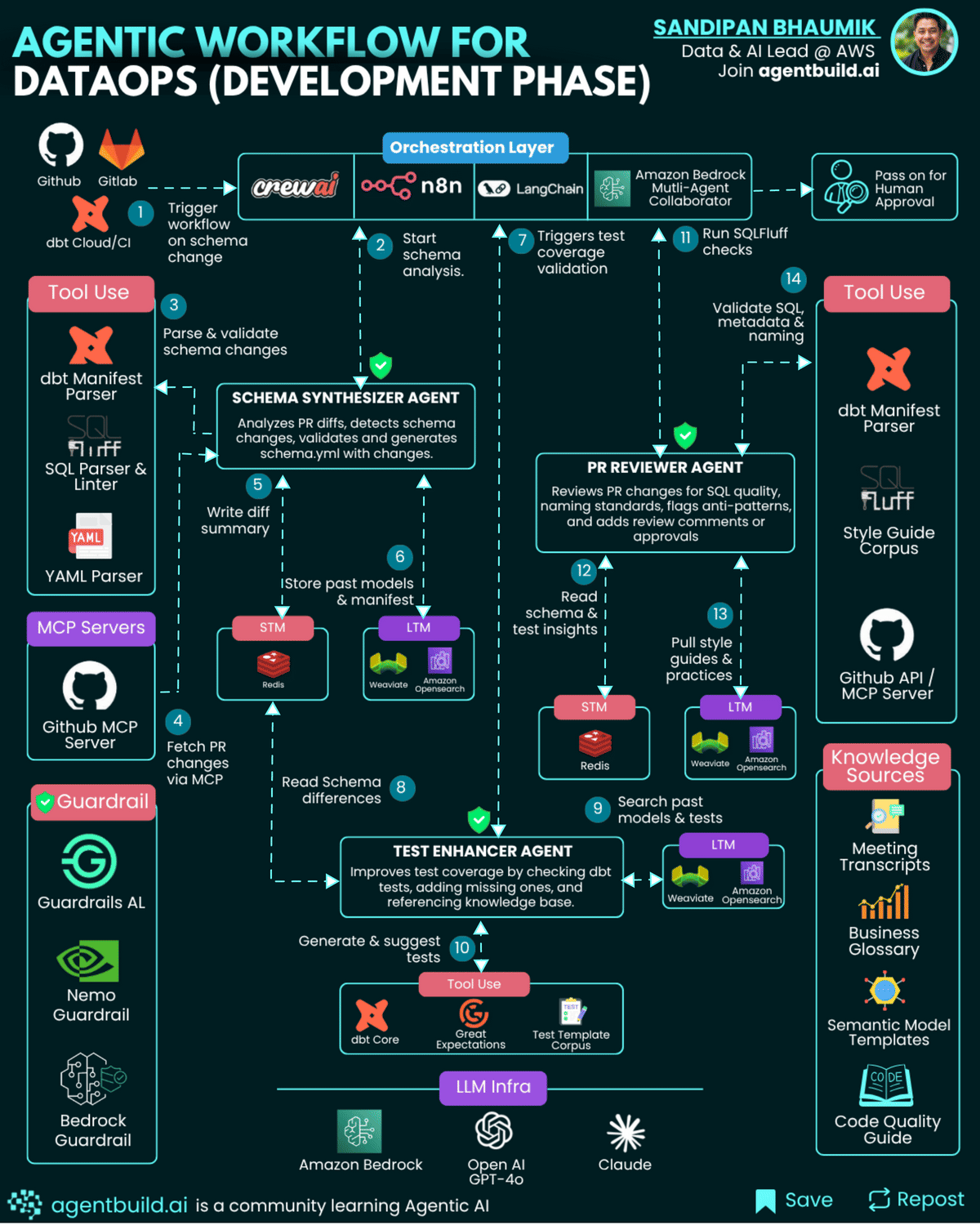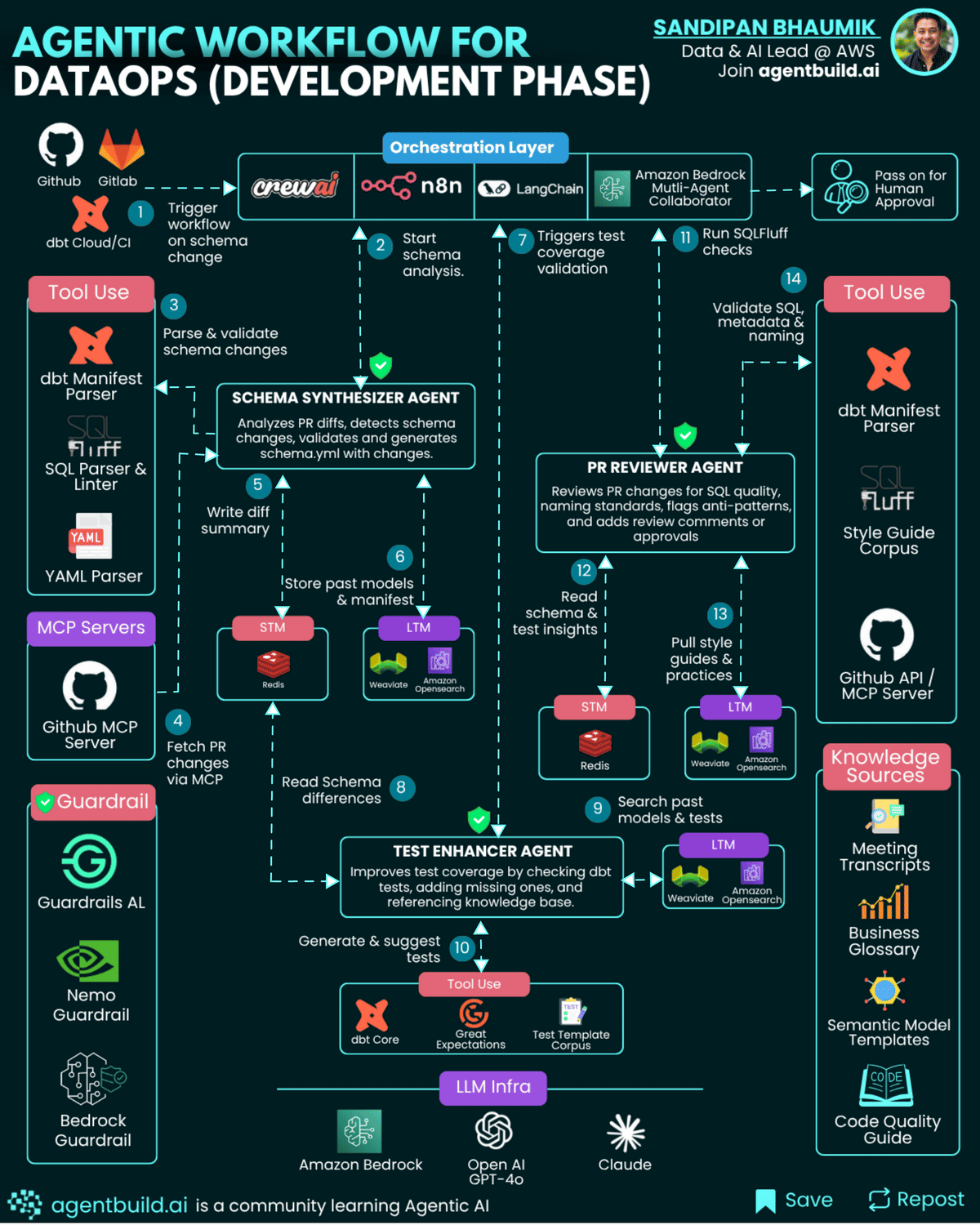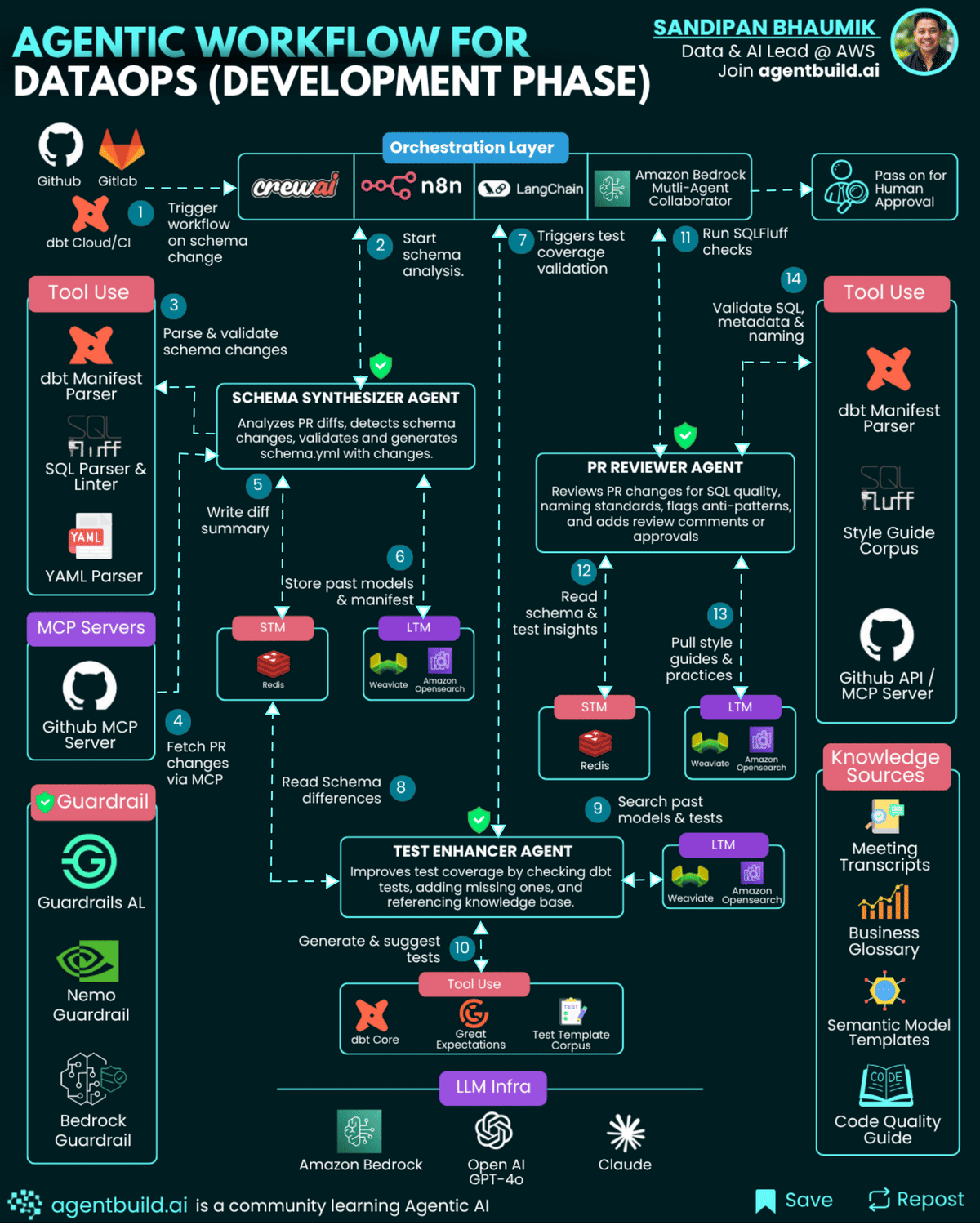
Agents and their Tool Use
1. Schema Synthesizer Agent
Data engineers often manually review pull requests to understand model or schema changes, then update schema.yml files and ensure consistency with organizational standards. This task can take hours and requires extensive tribal knowledge.
The Schema Systhesizer Agent automates detection of changed fields and models in PRs, updates schema.yml files automatically, and validates using dbt CLI. This saves engineers from repetitive manual edits, reduces schema drift, and ensures adherence to naming conventions.schema_synthesizer_agent = AgentExecutor(
llm=llm,
tools=[github_tool, dbt_tool, metadata_lookup],
prompt="""
Detect schema changes from GitHub PR, update schema.yml,
validate using dbt CLI, and enforce metadata standards.
"""
)The agent needs to use certain tools to do its tasks. Tools used in this blog are illustrative, the choice of tools depends on multiple factors and would very between organizations.
Tool Use:
Integration Example:
# Pseudo-code to integrate GitHub API and dbt
from github import Github
import subprocess
g = Github("access_token")
pr = g.get_repo("org/repo").get_pull(123)
diff_files = [f.filename for f in pr.get_files()]
# dbt compile to validate
subprocess.run(["dbt", "compile"])2. Test Enhancer Agent
Ensuring proper test coverage is tedious and often overlooked. Engineers manually write tests for new columns, unique constraints, and freshness checks.
This agent analyzes changed models for missing tests, references historical test patterns from Vector DB, and auto-generates tests (not_null, unique, accepted_values) using dbt or Great Expectations. This increases data quality and reliability without relying on human memory or manual effort, ensuring each change is fully tested.
#sample code
test_enhancer_agent = AgentExecutor(
llm=llm,
tools=[vector_db_tool, dbt_test_tool],
prompt="""
Analyze dbt models for missing tests, generate new tests
using Great Expectations or dbt CLI, and output updated test YAML.
"""
)Tool Use:
Integration Example:
# Fetch test patterns from Vector DB
patterns = vector_db.query("missing tests for model X")
# Generate dbt tests
subprocess.run(["dbt", "test", "--select", "model_name"])3. PR Reviewer Agent
Senior engineers manually review code for SQL style, metadata consistency, and lineage verification. This process is subjective, slow, and dependent on individual reviewer expertise.
The PR Reviewer Agent Runs SQLFluff lint checks, verifies lineage via OpenMetadata, and posts structured review comments directly to GitHub PRs. This speeds up review cycles, enforces consistent coding practices, and frees human reviewers to focus on complex business logic rather than style issues.
#sample code
pr_reviewer_agent = AgentExecutor(
llm=llm,
tools=[sqlfluff_tool, metadata_tool, github_comment_tool],
prompt="""
Run SQLFluff for style linting, verify lineage via OpenMetadata,
and post review comments on the GitHub PR.
"""
)Tool Use:
Integration Example:
# Run SQLFluff for linting
subprocess.run(["sqlfluff", "lint", "models/"])
# Post review comment
pr.create_review(body="Check SQL style issues", event="COMMENT")Memory Architecture
Memory is the backbone of context-aware agents. It enables them to recall previous interactions, organizational standards, and past review outcomes to make intelligent decisions:
Short-Term Memory (STM): Implemented via Redis or similar in-memory databases, STM tracks transient workflow state like active PR diffs, temporary schema information, and agent task progression. This data is cleared after workflow completion.
Long-Term Memory (LTM): Managed using a Vector DB (Weaviate, OpenSearch, Pinecone, Qdrant), LTM stores:
Past PRs and review comments for contextual guidance.
Historical model schemas and test coverage patterns.
Organizational code style guidelines and lineage graphs.
Memory ensures the right context is injected into each agent’s prompt. For example:
context = vector_db.query_embeddings("schema changes similar to PR 123")
agent_input = f"Use the following context for guidance:\n{context}\nTask: Update schema.yml"A critical enhancement is the ingestion of supporting documents like design docs, data dictionaries, and code review playbooks into the knowledge base. This provides rich, semantic context for agents when:
Suggesting schema changes.
Generating tests aligned with business rules.
Validating lineage and metadata.
This enhances decision-making, ensures outputs align with business practices, and allows the system to learn from every interaction over time.
Benefits
Developers: Automates schema updates and test creation.
Reviewers: Focuses human input on strategic review.
Leaders: Faster PR cycle times, higher code quality.
System: Learns and improves through every PR, making agents smarter over time.
Final Thoughts
The development phase is a critical bottleneck in DataOps. Introducing intelligent, tool-integrated, memory-augmented LLM agents could:
Automate repetitive tasks.
Enforce standards consistently.
Elevate human contribution to high-value engineering work.
Implementing this requires reliable agent coordination, robust integration with CI/CD, guardrails for safe commits, continuous monitoring, evaluation, and agent performance tuning.
While tools like CrewAI, LangChain, Bedrock Agents, and MCP servers enable this - fully autonomous multi-agent DataOps development would require incremental experimentation.
This is a forward-looking concept that could shape the future of DataOps automation as agent frameworks and integrations mature.
Leave your feedback on comments. Let's discuss how we could innovate further.