
Decision Traces: The Missing Black Box ✈️ for AI Agents
Decision traces explained - what they are, why every consequential AI agent needs them, and the architecture that makes reasoning auditable, defensible, and improvable.
Hey everyone,
Hope you all are doing well. Today, I am bringing up something that is increasingly coming up in my customer discussions. Not everyone is giving it a name, but the requirements they define clearly point to building Decision Traces.
Let me explain.
Flight data recorders (FDR) are popularly know as the black box of the aircraft. Technically the black box contains the FDR and the Cockpit Voice Recorder (CVR). The FDR turns raw sensor traces into timelines that explain crashes, reveal root causes, and drive global aviation safety improvements. Before flight data recorders were mandated, when something went wrong, investigators worked from witness accounts, wreckage patterns, and whatever instruments happened to be installed at the time. The analysis was mostly incomplete, often contradictory, and it rarely led to systemic changes.

The aviation industry knew flying was becoming more consequential with more routes, more passengers, more complex airspace, but the infrastructure to understand why things failed hadn’t kept pace with the deployment of the systems themselves. It was invented in response to the recognition that consequential systems operating at scale need a structured record of their reasoning - not just their outcomes.
AI agents are at the same inflection point today. And the industry, especially in the regulated space is recognizing that.
What’s the gap right now?
An AI agent deployed in a production system today typically produces two things: an input log and an output. What it doesn’t produce is the reasoning chain between them in any structured, queryable, auditable way .
This gap has a name. It’s called Decision Debt, one of the three categories of debt that block AI from working in production. Decision Debt accumulates when you build and deploy AI systems before defining how decisions get made, recorded, and reviewed. It’s not a future problem. It’s accumulating now, in every agent deployment that ships without trace infrastructure.
A decision trace is the record of how an agent got from context to conclusion: what it knew, what it considered, what it weighted, what it discarded, and at what confidence level it committed to an action.
IMPORTANT: It’s not a log file. Logs capture events. Traces capture reasoning.
The distinction matters because when something goes wrong - and in any system operating at scale, you need to answer a different set of questions than a log can address.
Answering “what happened” is not enough, but “why did the agent conclude that, given what it had access to?” matters more.
This is a historical pattern
Aviation gets to the black box through painful iteration. Financial services gets to trade surveillance infrastructure the same way. Healthcare builds clinical decision support audit trails only after near-misses force the question.
The pattern across every regulated industry is identical: consequential system deploys, operates without adequate observability, incident occurs, retroactive audit reveals the trace infrastructure was never built, expensive fixes follow.
What’s different with AI agents is that we can see this pattern coming before the incidents accumulate. The decision trace problem is visible now, in advance, to anyone who has watched the previous cycles play out in adjacent domains.
Nuclear power operations built decision logging infrastructure into control room design before widespread deployment. And that’s not because regulators demanded it initially, but because the engineers understood that a system making consequential decisions in real time needed to be interrogable after the fact.
The Chernobyl investigation was partially possible because operator actions were timestamped and sequenced. The lessons extracted shaped reactor design globally.
The equivalent for AI agents isn’t complicated in principle.
It is, however, work that almost nobody has started.
What Decision Trace Infrastructure actually need?
The architecture for a decision trace system has five functional layers, and each one has a specific job. Here’s how they fit together.
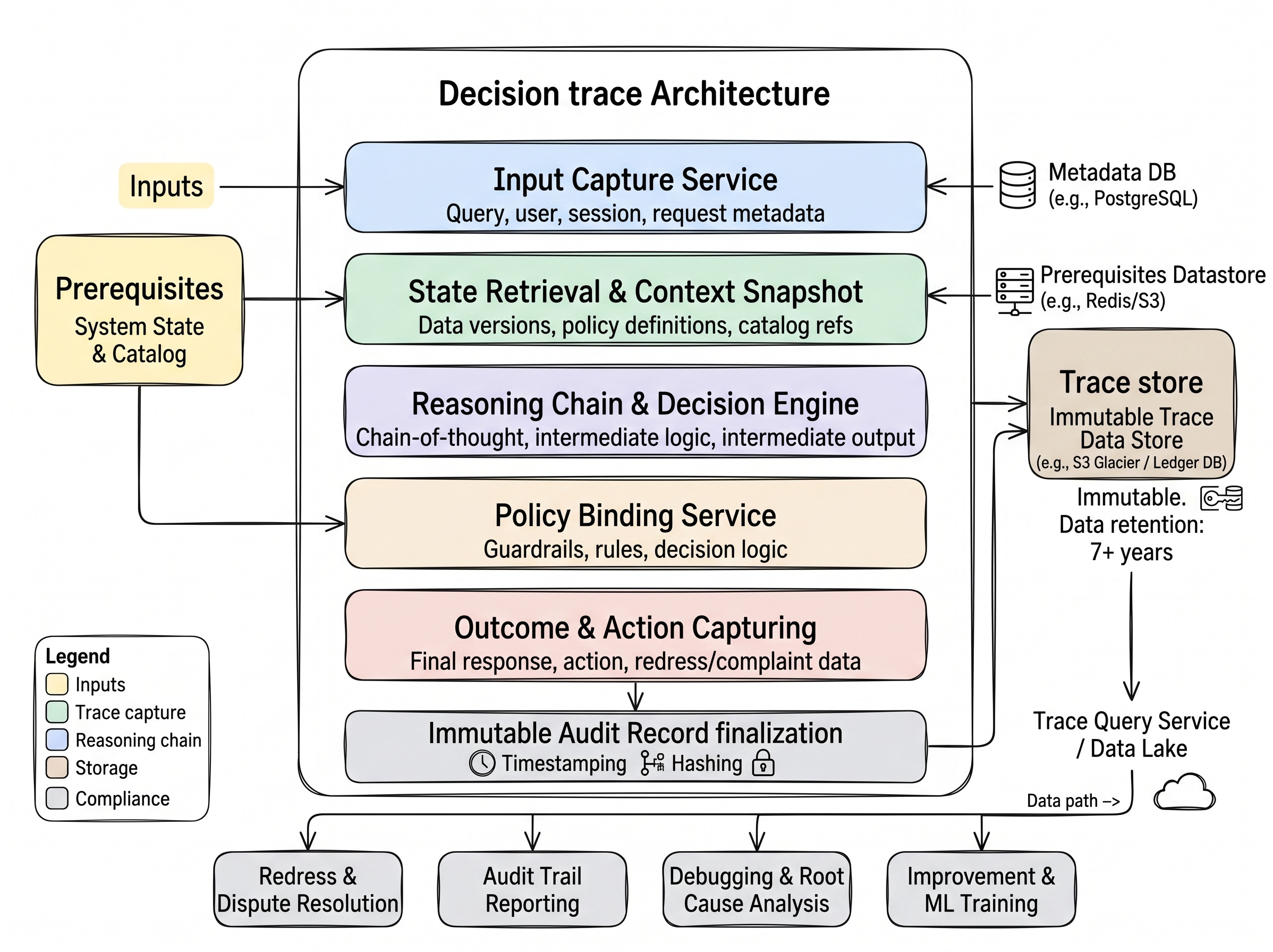
Input Capture Service is where the trace begins - at the moment a request enters the system. Query, user identity, session context, and request metadata are captured here, backed by a metadata store (PostgreSQL can be a straightforward choice). This is the “who asked what, when, and from where” layer. Without it, you have no anchor for the rest of the trace.
State Retrieval and Context Snapshot captures the world as the agent saw it at decision time: which data versions were active, which policy definitions were in force, which catalog references were resolved. This layer pulls from a prerequisites datastore - Redis for low-latency state, S3 for snapshot durability. It’s also the layer that makes post-incident analysis possible. When you need to understand why the agent concluded what it did three months ago, you need to know what it knew at that moment - not what the system knows now.
This layer is, in practical terms, where a context graph lives - even if most implementations don't call it that yet. A context graph is simply the structured representation of what the agent knew and how those things related to each other at decision time: data assets, policies, catalog nodes, versions, and their connections. The reason "context graph" is gaining traction as a term without a settled definition is precisely because this layer has been missing from most agent architectures. Once you build the snapshot layer properly, you have one.
Reasoning Chain and Decision Engine is the core trace layer. Chain-of-thought steps, intermediate logic, intermediate outputs - all captured as structured records. It is the path the agent took to reach the final answer. Every branch, every intermediate conclusion, every tool invocation that shaped the reasoning is an addressable record here.
Policy Binding Service records the guardrails, rules, and decision logic that were active during the reasoning process. This is what separates a decision trace from a debugging log. You’re not just capturing what the agent did, you’re capturing the constraints it was operating under. When a compliance team asks “was the agent following the policy that was in force on this date,” this layer answers that question directly.
Outcome and Action Capturing records the final response, the action taken, and critically - any redress or complaint data attached to that outcome. This closes the loop between the agent’s decision and its real-world consequence. It’s also the layer that feeds dispute resolution workflows when customers or regulators challenge an outcome.
All five layers feed into an Immutable Audit Record - timestamped, hashed, and written to an immutable trace store (S3, Delta Lake or a ledger database). The immutability is a must-have. It is the architectural guarantee that the record cannot be altered after the fact, which is what makes it defensible in a regulatory or legal context. The diagram you see specifies retention period, which aligns with financial services conduct requirements and is a reasonable baseline for any regulated environment.
From the trace store, a Trace Query Service and Data Lake make the records queryable at scale. This is the operational distinction you need to understand. A queryable trace lets you ask: “Show me every decision where the policy binding service applied rule X and the outcome was Y.” That’s the difference between evidence and insight.
The four downstream outputs from this architecture tell you exactly what it’s designed to serve: Redress and Dispute Resolution (when a decision is challenged), Audit Trail Reporting (when a regulator asks), Debugging and Root Cause Analysis (when something fails), and Improvement and ML Training (when you want to make the system better using real decision data).
No single layer here is novel in isolation. Input capture, immutable storage, policy versioning exist in adjacent systems already. What doesn’t exist yet, in any standardised form for AI agents, is this stack assembled as a coherent, purpose-built trace infrastructure. That’s the gap this architecture closes.
Why enterprise architects need to move on this now
This infrastructure is necessary to build the cleanest parth through regulatory scrutiny, incident response, and enterprise customer due diligence. The same principle made structured engineering logging standard practice in distributed systems. You cannot debug what you cannot observe. You cannot improve what you cannot measure. And you cannot defend in a board meeting, a regulatory inquiry, or a customer audit what you never recorded.
Decision traces are the observability layer for AI reasoning. It is the infrastructure equivalent of distributed tracing in microservices, now applied to systems that don’t just execute code, but form conclusions and take actions.
The good news is that this is buildable now, with current tooling, before the incidents force it. The question is whether engineering organisations treat it as foundational infrastructure from the first production deployment, or discover its absence after the fact.
Call To Action
If you are building AI agents for anything consequential, the time to design trace infrastructure is before the first production deployment. Start by mapping which decisions your agent makes that you could not currently explain, audit, or defend: that list is your build priority.
If this framing is useful, share it with the architect or engineering lead on your AI team - this is the conversation that needs to happen before the system goes live, not after.
Leave a feedback or comment. Share your opinion about this topic.
Thanks,
Sandi.
👉 You might also find my article published on Atlan’s community Substack useful:

P.S. If you’re new here - welcome 🎉. AgentBuild is a community of practitioners working through the real challenges of getting AI into production inside large organisations. Every week I share practical, grounded thinking from the people doing this work at the sharp end. The goal is never theory - it’s always: what can you use Monday morning.
Ask your friends to join.
More valuable content coming your way.
Thanks for reading agentbuild.ai! Subscribe for free to receive new posts and support my work.