
How Do You Test AI - Practical Talk on AI Evaluation Approaches
What Hamel Husain taught me about why most enterprise AI systems fail - and the one habit that fixes it. Don't miss it.
Hello everyone,
Last week, I sat down with Hamel Husain for the AgentBuild podcast. Hamel is one of the most influential voices on AI evaluation in the industry right now - the kind of person that other experts quote when they’re trying to explain something difficult. The conversation was one of the most practically useful I’ve had this year, and I want to share the best of it with you.
Who is Hamel Husain?
Hamel is a machine learning engineer with over 20 years of experience. He’s worked at Airbnb and GitHub - where his early LLM research contributed to what eventually became GitHub Copilot. He has led and contributed to popular open-source ML tools, and today he’s an independent consultant who has helped more than 35 organisations build real-world AI products that actually perform in production.
He co-teaches AI Evals for Engineers and PMs on Maven, a course with over 3,000 students from 500+ companies - including teams at OpenAI, Anthropic, and Google. He also writes one of the most substantive technical blogs in the AI space at hamel.dev, and is co-authoring an O’Reilly book on the subject - Evals for AI Engineers.
He is, in short, the person you call when your AI system’s quality is a mystery.
The biggest misconception about AI evaluation
I asked Hamel what the most common mistake is when enterprises approach evaluation. He didn’t hesitate.
“The biggest misconception is that evaluation is as easy as going to a vendor that will give you off-the-shelf metrics in a dashboard. You plug it in, and poof - you’ve done eval. You’ve checked the box.”
He’s seen this play out more times than he can count. The team wires up a platform. They get a dashboard with coherence scores, faithfulness scores, toxicity scores. Everyone feels good for the first week. And then, slowly, people start to realise: those numbers don’t mean anything. No one knows what they’re measuring. They can’t tell if the product is getting better or worse.
Generic metrics don’t correlate to what matters for your specific application. A hallucination score doesn’t tell you if your legal AI is giving dangerous advice. A coherence score doesn’t tell you if your scheduling assistant is actually booking the right slots.
As Hamel puts it: “When I see a company showing me only generic metrics, I already know they’re in trouble. There’s a direct correlation between generic dashboards and teams that feel lost.”
Foundation model evals vs. product evals
There’s a second source of confusion worth naming. When people hear the word ‘evaluation’, many think of the benchmarks that model providers publish - things like MMLU, SWE-Bench, HumanEval. These are foundation model evals. They measure the general capabilities of a model at large. They have almost nothing to do with how well your AI product performs for its specific purpose.
Hamel’s analogy is the one I’ll keep using: Foundation model evals are like a standardised test score. Product evals are like job performance. Your SAT score tells you very little about whether you’ll be a good engineer. The gap between the two can be enormous.
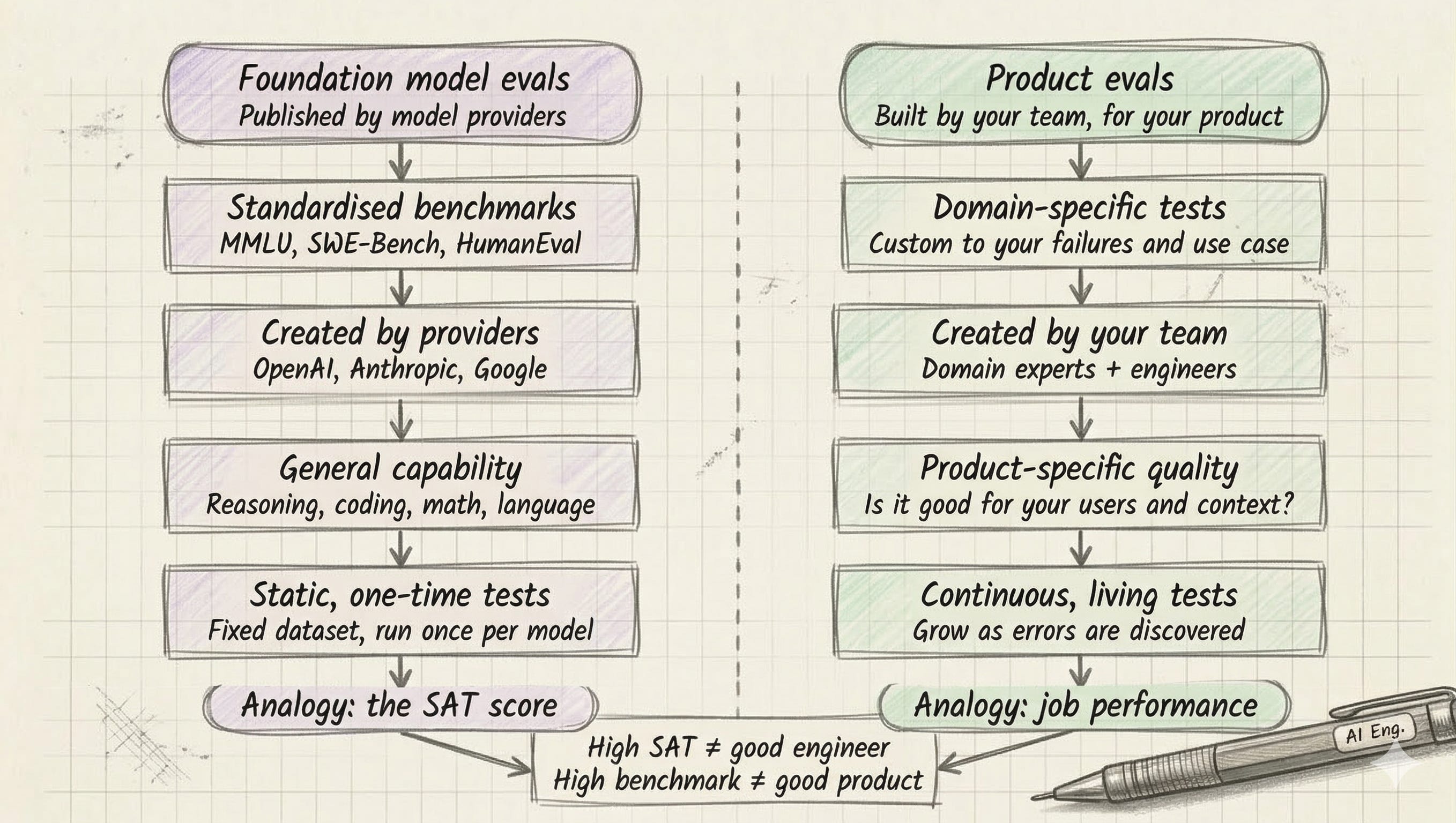
What matters for the enterprise is the second kind. Not ‘how capable is GPT-5 generally?’ but ‘is our claims-processing assistant handling edge cases correctly, and can we measure that consistently?’
Why traditional QA isn’t enough
One of the most common objections I hear from customers: “We already have a QA team. Why can’t they just test the AI?”
Hamel’s answer is direct: treating AI evaluation like traditional software testing is a fundamental mistake.
The reason is determinism. Traditional software has deterministic outputs. You write a unit test: given input X, expect output Y. Pass or fail. With AI, the output is stochastic by design. The system is explicitly built to produce varied responses. You can’t write a unit test for a stochastic system the same way.
What you need instead is something that already exists - but that most AI teams have left behind: data science thinking.
Data scientists have been measuring stochastic systems for decades. They know how to sample, analyse, spot patterns, and design experiments that account for variability. That entire discipline is exactly what’s needed for AI evaluation. We just need to adapt it slightly for LLMs.
Hamel summarises it simply: “Evals are essentially data science for AI.”
The eval loop - how it actually works
Before I go further, let me show you the structure of a proper evaluation loop. This is what we explored together on the podcast earlier this week:
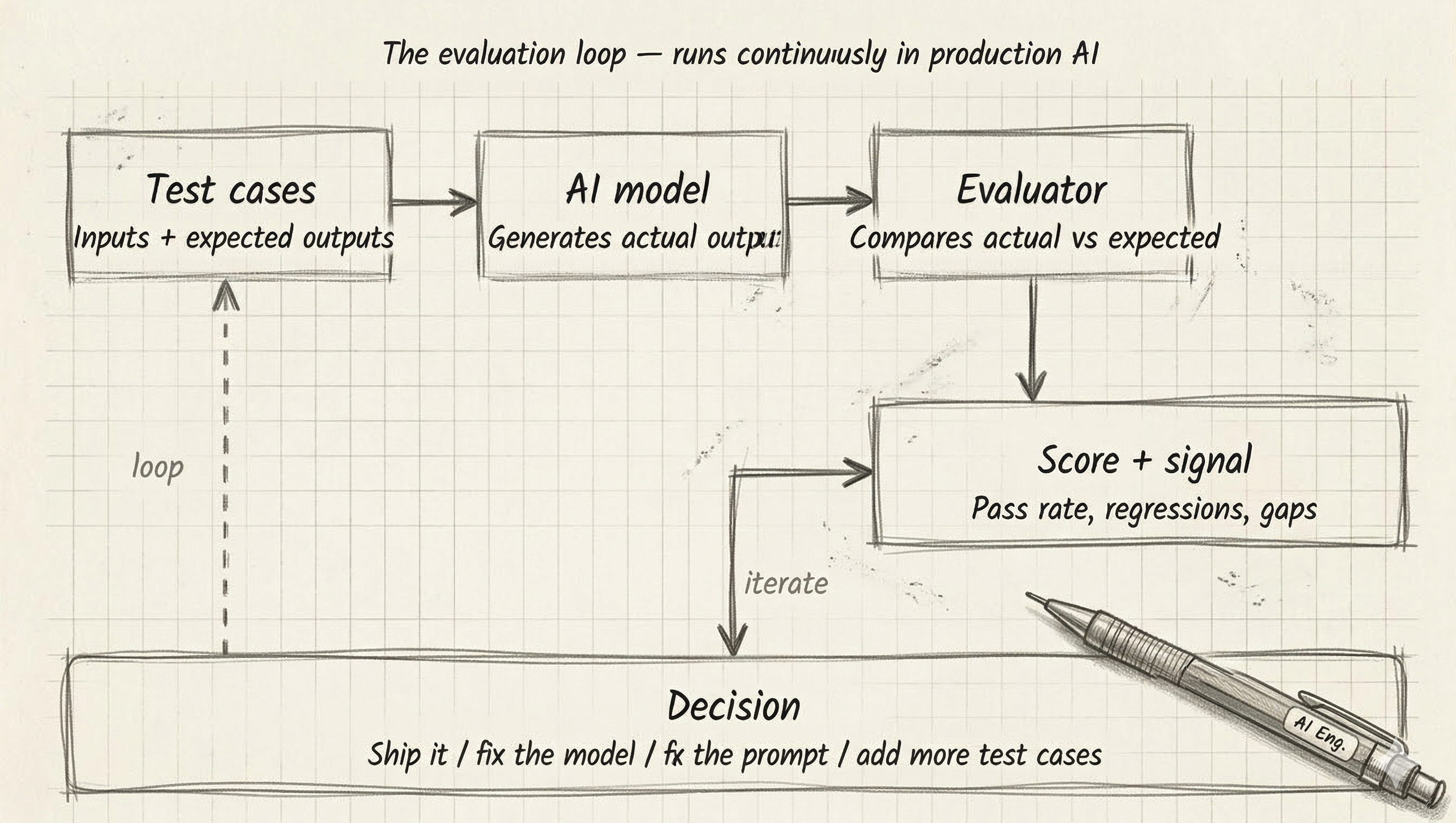
The loop is simple in principle. You feed test inputs into your model. You compare what it produces to what you wanted. You score the gap. And you use that signal to decide what to change - the prompt, the model, the data, or the test cases themselves.
The hard part is what lives inside the “evaluator” box. There are four types of evaluators, each with different trade-offs:
Exact match - Deterministic scoring. The output must match the expected answer. Fast and cheap, but brittle. Works well for classification, SQL, and structured outputs. Falls apart when the answer is right but worded differently.
Heuristic - Rule-based checks. Regex patterns, keyword presence, schema validation, length constraints. Good for catching structural failures. Can’t evaluate meaning.
Human review - Real people read outputs and rate them. The highest nuance. Also the slowest and most expensive. Essential for calibrating everything else, but doesn’t scale to thousands of daily outputs.
LLM-as-judge - A second AI model evaluates the output against a rubric. Scales well, handles open-ended responses, captures nuance that heuristics miss. But it inherits the judge model’s biases and blind spots. Requires calibration against human labels.
In practice, mature teams use all four. Exact match and heuristics form the fast, cheap baseline. LLM-as-judge handles scale on open-ended outputs. Human review calibrates the judge periodically.
The most powerful habit in AI development
Here’s where Hamel said something that sounds counterintuitive - and that I think is the single most important insight from our conversation.
The highest-value activity you can do when building an AI product is to sit down and look at your data.
Just open your traces, read actual outputs, and write down what you see.
When most people hear this, something in them resists. “In the age of AI, you’re telling me to open a spreadsheet and read individual data points? That can’t scale.”
But Hamel has done this with more than 50 companies. Every single time, people discover it’s not just useful - it’s transformative. They find unexpected failure modes. They identify bugs they didn’t know existed. They develop intuition that no automated system would have surfaced.
And there’s a second reason it matters: looking at data is how you elicit your own requirements. This is what Hamel calls criteria drift. You can write a specification about what a good product looks like. But it’s only when you see real user interactions that you understand what “good” actually means for your context. The process of reading real outputs and writing down what you observe is the process of transferring your taste to the system.
His practical starting point: aim to read at least 100 traces. 100 is not a magic number, it’s a concrete goal that gets people started. Keep reading until you reach what he calls theoretical saturation - the point where new traces aren’t revealing new failure patterns. In his experience, people rarely want to stop.
Who should own evaluation - and how to champion it
The other question I pressed Hamel on was organisational. In a large enterprise with 50 AI use cases in the pipeline, who owns this? Is there a central eval function? Does it sit with a team or a role?
He’s a strong advocate for bottom-up adoption, not centralised mandates. Top-down approaches - “our platform will standardise eval across the organisation” - tend to produce checkbox compliance. Teams grudgingly report metrics nobody understands.
What actually works: start needs-based. One team, one product, one clear problem they’re trying to debug. Embed the evaluation practice into the building process - not as a separate audit step, but as part of how they iterate.
Evaluation must be owned by domain experts, not outsourced to a QA or engineering team. If it’s a legal assistant, a lawyer needs to be in the loop. If it’s a clinical tool, a clinician. The domain expert is the only person with the taste and judgment to say whether an output is genuinely good. The engineering team can build the infrastructure, but the ground truth comes from the domain.
As for championing it internally? Hamel’s advice is the same I’d give for any new practice: don’t sell the methodology. Sell the results.
Don’t walk into a meeting saying “we need to do evals.” Walk in with findings. Show the error rate you found. Show the specific failure pattern you fixed. Show how you caught a regression before it went to production. Once people see that you consistently know more about what the product is actually doing than anyone else in the room, they’ll ask how.
What this means for your enterprise AI programme
If I were to distil everything Hamel shared into the things you can actually act on this week, here’s how I’d frame it:
Resist the pull of generic dashboards. If your only eval metrics are off-the-shelf coherence and faithfulness scores, you’re not evaluating - you’re performing evaluation. The metrics that matter are the ones you derive from looking at your own system’s failures.
Spend 30 minutes this week reading traces from one of your AI systems. Don’t automate it yet. Just read. Write down what you notice. You’ll find things no algorithm would have flagged.
Identify your domain expert. For every AI use case you’re building, there should be a person who has the authority and the proximity to say whether an output is good. That person needs to be in the loop on evaluation, not just the engineering team.
When you want to bring others along, don’t present a methodology deck. Present results. Show the before and after. Lead with what changed for the user or the business, and let the process speak for itself.
If you haven’t listened to my conversation with Hamel yet, I’d encourage you to. It’s one of the best discussions I’ve had on what it actually takes to build AI systems that hold up in production - not just in the demo.
I’d love to know what resonated. Reply to this email or comment here - looking forward.
Talk soon,
Sandi
P.S. If you’re new here - welcome 🎉. AgentBuild is a community of practitioners working through the real challenges of getting AI into production inside large organisations. Every week I share practical, grounded thinking from the people doing this work at the sharp end. The goal is never theory - it’s always: what can you use Monday morning.
Ask your friends to join.
More valuable content coming your way.
Thanks for reading agentbuild.ai! Subscribe for free to receive new posts and support my work.