
The Complete Map of LLM Practices (Prompting → RAG → Fine-tuning)
Inside: Most production LLM apps use just 3 of these 7 practices. Find out which ones (and why you probably don't need fine-tuning yet). Diagrams included.

Hey AgentBuilders,
In my day to day conversations, I spend a lot of time explaining the different practices when companies embark on building applications using LLMs. A lot of those conversations are about explaining trade-offs at production-scale. So, I thought today, I’ll jot down some field notes for you, explaining the seven common pratices, when you need them, and how to choose between them. Obviously, this is high-level and there are many more nuances that I can’t fit in an article, but this should give you some direction.
Today I answer the following questions that often come up in my meetings:
Should I start with RAG or fine-tuning?
When is prompt engineering “enough”?
Why do my LLM outputs feel “off”?
What’s the minimum viable stack for production?
How much will each practice actually cost me?
The Seven LLM Practices You Actually Need to Know (And When to Use Them)
Hey there,
If you’re building with LLMs right now, I’m guessing you’ve felt that familiar confusion: there’s so much happening, so many terms flying around, and everyone seems to be doing something different. Should you be fine-tuning? What’s this RAG thing everyone keeps mentioning? Is prompt engineering enough? What even is a vector database, and do you really need one?
I get it. The LLM space moves fast, and the practices feel tangled together. But here’s the thing - they’re actually distinct skills that solve different problems. And once you see how they fit together, everything clicks.
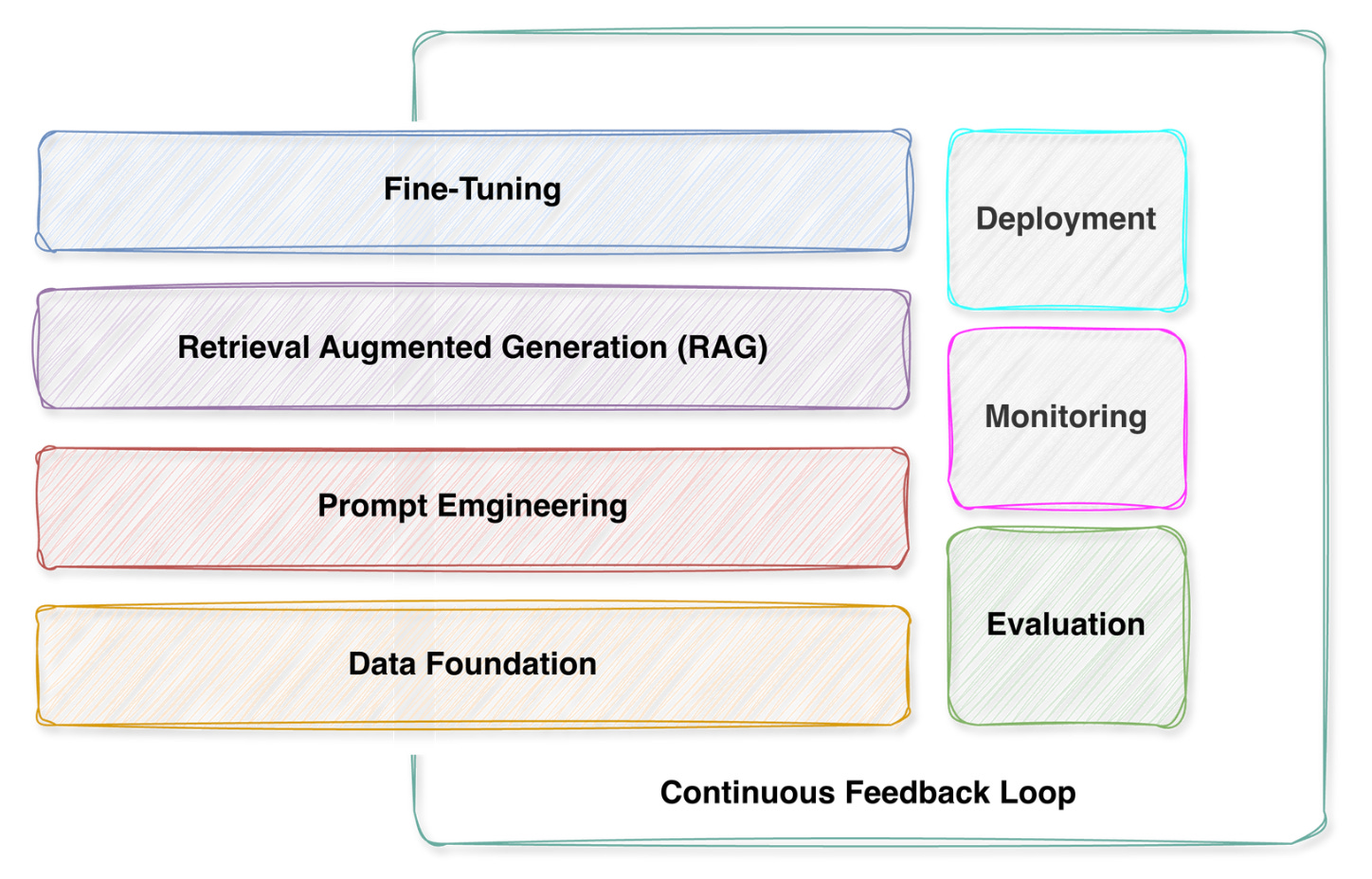
Think of this as your map. I’m not here to sell you on complexity - I’m here to help you see clearly which practice solves which problem, so you can stop second-guessing and start building with confidence.
1. Data Foundation: Yes, You Still Need Good Data
Let’s start with the unsexy truth: data pipelines are about getting your data ready - cleaned, formatted, and organized - whether you’re fine-tuning a model, building a RAG system, or just preparing quality examples.
Here’s why it matters to you: Remember that time your model hallucinated something completely wrong, or gave wildly inconsistent answers? Yeah, that’s often a data problem. Garbage in, garbage out isn’t just a saying - it’s the #1 reason LLM projects fail quietly.
You’re dealing with things like sourcing the right documents, cleaning up duplicates, chunking text for retrieval, creating embeddings, formatting everything so the model can actually use it (hello, JSONL files), and keeping track of versions as things change. For RAG systems, this means setting up vector databases and ensuring your knowledge base is actually retrievable.
The reality check: For fine-tuning especially, 500 carefully chosen examples will beat 10,000 random ones every single time. For RAG, poorly chunked documents or bad metadata will make your retrieval useless. Quality over quantity isn’t motivational poster wisdom - it’s how you save weeks of debugging.
You’ll know you need this when: Your model’s outputs feel “off,” you’re about to fine-tune, you’re building a RAG system, or your search results are returning irrelevant content.
2. Prompt Engineering: Your Superpower (Seriously)
This is where most of you should start, and honestly, where many of you should stay for longer than you think. Prompt engineering is about crafting the right input to get the output you need - without touching the model itself.
Why you should care: This is your fastest route to results. A well-crafted prompt can take you from “this doesn’t work” to “holy shit, this actually works” in an afternoon. And it costs almost nothing compared to fine-tuning or training models.
We’re talking system prompts that set the vibe, few-shot examples that show the model what you want, chain-of-thought prompting that makes it think through problems step-by-step, and structured outputs so you can actually parse the responses.
Watch this webinar o Prompt Engineering to learning the basics.
Real talk: Most people start with random prompting and think “this is fine.” But when you’re running this in production with thousands of users? You need version control, you need testing, you need to know why prompt A works better than prompt B.
You’ll know you need this when: You’re literally talking to an LLM right now. This is your entry point. Master this before you jump to anything more complex.
3. RAG (Retrieval-Augmented Generation): Give Your Model a Memory
RAG is about connecting your LLM to external knowledge - retrieving relevant information from your documents, databases, or knowledge bases and injecting it into prompts so the model can answer with current, specific information it wasn’t trained on.
Why this is a game-changer: Your base LLM doesn’t know about your company’s internal docs, your product specs, or anything that happened after its training cutoff. RAG solves this without retraining. It’s how you build chatbots that know your documentation, customer support that references your actual policies, and applications that work with proprietary data.
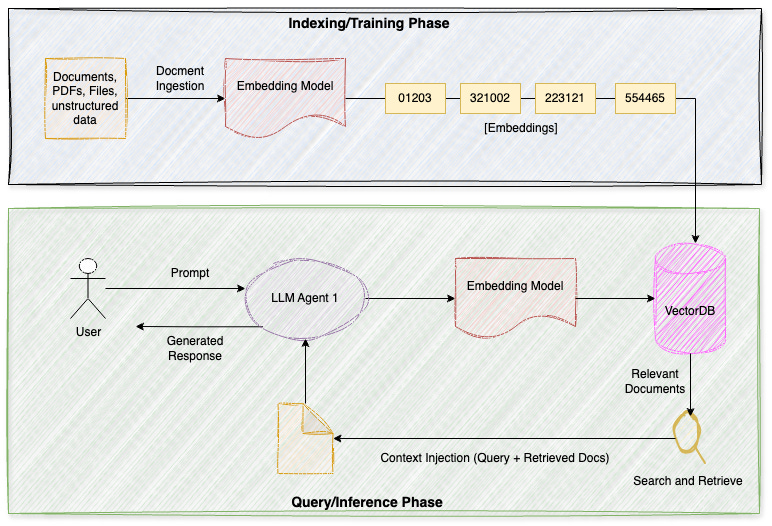
You’re setting up vector databases (e.g. Pinecone, Weaviate, Chroma), creating embeddings of your documents, implementing semantic search to find relevant chunks, and engineering prompts that effectively use the retrieved context. The magic is in the retrieval quality - if you pull the wrong documents, the model gives wrong answers.
The honest truth: RAG is often the right answer before you even think about fine-tuning. It’s more flexible (update your knowledge base without retraining), cheaper to maintain, and handles changing information naturally. Most production LLM apps use some form of RAG.
You’ll know you need this when: Your prompts work great but the model lacks specific knowledge, you need answers based on proprietary documents, or you’re constantly updating information that the model needs to know.
4. Fine-tuning: When RAG and Prompting Aren’t Enough
Fine-tuning is training a model on your specific data to change its behavior - making it talk like your brand, understand your domain’s nuances, or consistently format outputs the way you need.
Why it matters to you: Sometimes prompts and RAG just can’t get you there. Maybe you need the model to always respond in a specific style, you have highly specialized terminology that even with context the model struggles with, or you’re making so many API calls that the costs are killing you and a smaller fine-tuned model would be cheaper.
You’re looking at techniques like LoRA (updating just small parts of the model) or full fine-tuning (the expensive option), and you need quality training data - see point #1.
The honest truth: Fine-tuning creates maintenance burden. You now own a custom model. When the base model improves, you need to re-tune. When your requirements change, you’re back to square one. And here’s the key decision: try RAG first. Seriously. RAG solves 80% of the problems people think require fine-tuning, with way less hassle.
You’ll know you need this when: You’ve exhausted prompt engineering and RAG, you need consistent outputs at massive scale, you need a specific tone/style that’s hard to prompt for, or you’re optimizing for cost with a smaller specialized model.
5. Evaluation: The Hard Part Nobody Talks About
Evaluation is figuring out if your model actually works before you ship it to users. And I’m not going to sugarcoat this - it’s the hardest part of working with LLMs.
Why you should lose sleep over this: You know what’s worse than a broken feature? A feature that seems to work in testing but falls apart with real users. LLM outputs are subjective, context-dependent, and full of edge cases you didn’t think of.
You’re building test datasets that reflect real usage, running benchmarks (MMLU, HumanEval), getting humans to rate outputs, checking retrieval quality in your RAG system, and maybe even using one LLM to judge another’s responses (wild, but it works). For RAG specifically, you need to evaluate both retrieval quality (did we find the right documents?) and generation quality (did the model use them well?).
Here’s what nobody tells you: Generic benchmarks are mostly useless for your specific use case. You’ll end up building custom evaluation frameworks that match what your users actually care about. It’s tedious. It’s essential. There’s no shortcut.
You’ll know you need this when: You’re about to ship to production and that voice in your head is asking “but does it really work?” Listen to that voice.
6. Deployment: Making It Real
Deployment is getting your LLM application running in production where real users hit it with real traffic - and you need it to be fast, reliable, and not bankrupt you.
Why this keeps you up at night: Everything works great in your Jupyter notebook with one request at a time. Production is 100 requests per second, users expecting responses in under a second, vector database queries that need to be lightning fast, and your AWS bill growing faster than your user base.
You’re choosing between managed APIs (OpenAI, Anthropic - easy but potentially expensive) and self-hosting (cheap at scale but operationally complex). You’re adding caching so you don’t re-compute the same thing twice. You’re optimizing your RAG pipeline so retrieval doesn’t kill your latency. You’re building fallbacks for when APIs go down. You’re rate limiting so one user can’t blow your budget.
The wisdom you need: Start with APIs. Seriously. Self-hosting sounds appealing (”we’ll save so much money!”) until you’re managing GPU infrastructure at 3am. Graduate to self-hosting only when you have real scale or strict data privacy needs.
You’ll know you need this when: You’re moving from prototype to production, your API bills are making your CFO ask uncomfortable questions, or users are complaining about slow response times.
7. Monitoring: Your Safety Net
Monitoring is watching what your model does in production. -tracking every request, measuring performance, catching problems before users complain. Monitoring is not new, everyone in tech know why this is important.
Why you can’t skip this: LLMs drift. User behavior changes. Edge cases emerge. That prompt injection attack you never thought about? You’ll only catch it if you’re logging and monitoring. Your RAG system returning worse results because your vector database is stale? You’ll only notice if you’re tracking retrieval quality. Your costs doubling overnight? You’ll only notice if you’re tracking.
You’re logging prompts and completions, measuring latency (including retrieval time for RAG), analyzing costs per request, scoring quality (automatically or with human review), tracking which documents get retrieved most often, and watching for anomalies.
The truth about monitoring: You think you can get away without it until something breaks and you have zero visibility into what went wrong. Then you’re debugging production issues by asking users “um, what exactly did you type?”
You’ll know you need this when: You’re in production. Period. I would say you will need this in testing - especially to test yout tracing logic is correct. This isn’t optional at scale - it’s how you know what’s actually happening.
Cost vs. Complexity: Where Each Practice Falls
Start in the bottom-left corner with prompt engineering-it’s cheap and simple. RAG sits in the middle (moderate complexity with vector databases, moderate cost with embeddings and storage), while fine-tuning and self-hosting live in the top-right corner as optimization plays for teams with resources and scale.
A note on Data Foundation: This one’s tricky to place because cost and complexity vary wildly based on your organization’s data maturity. If you already have solid data infrastructure, adding LLM-specific pipelines might be straightforward. If you’re starting from scratch with messy data across siloed systems, it can become one of your most complex and expensive efforts. Your mileage will vary dramatically here.
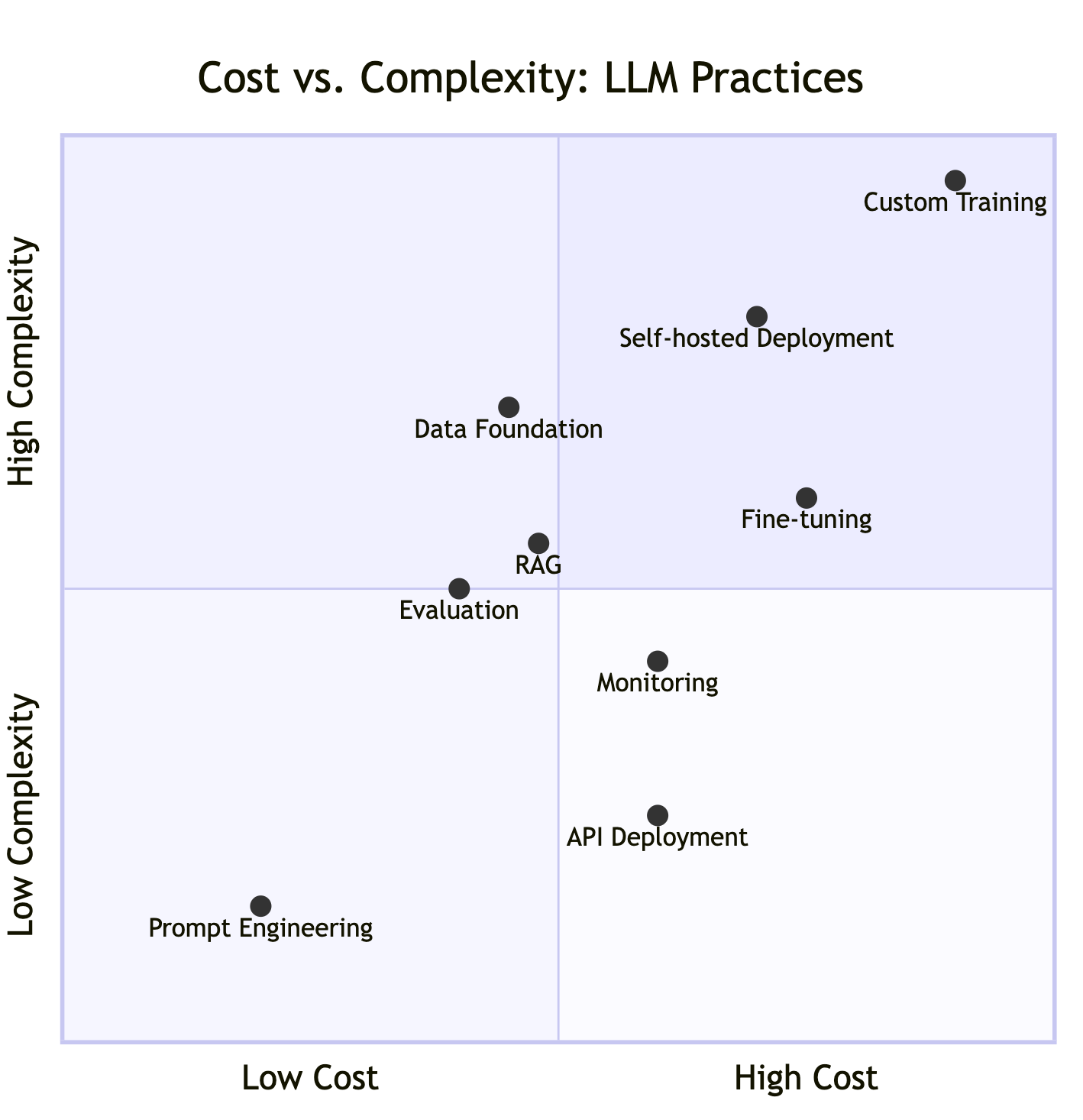
Most teams never need to leave the left side of this chart.
This explains:
Where to start (bottom-left)
Where RAG fits (middle ground)
Where the expensive stuff lives (top-right)
The key insight: most teams don’t need the complex/expensive stuff
How to Get Started And Keep Evolving
Look, you don’t need to master all seven practices tomorrow. You need to know which one solves your current problem.
Just starting? Master prompt engineering. Get really good at it. You’ll be shocked how far it takes you.
Need external knowledge? Build a RAG system before you even think about fine-tuning. It’s almost always the right next step.
Shipping to users? Focus on evaluation and deployment. Make sure it works, then make sure it stays working.
Scaling up? Now monitoring becomes critical. You need to see what’s actually happening.
Optimizing for cost or highly specialized behavior? That’s when fine-tuning and advanced data pipelines come into play.
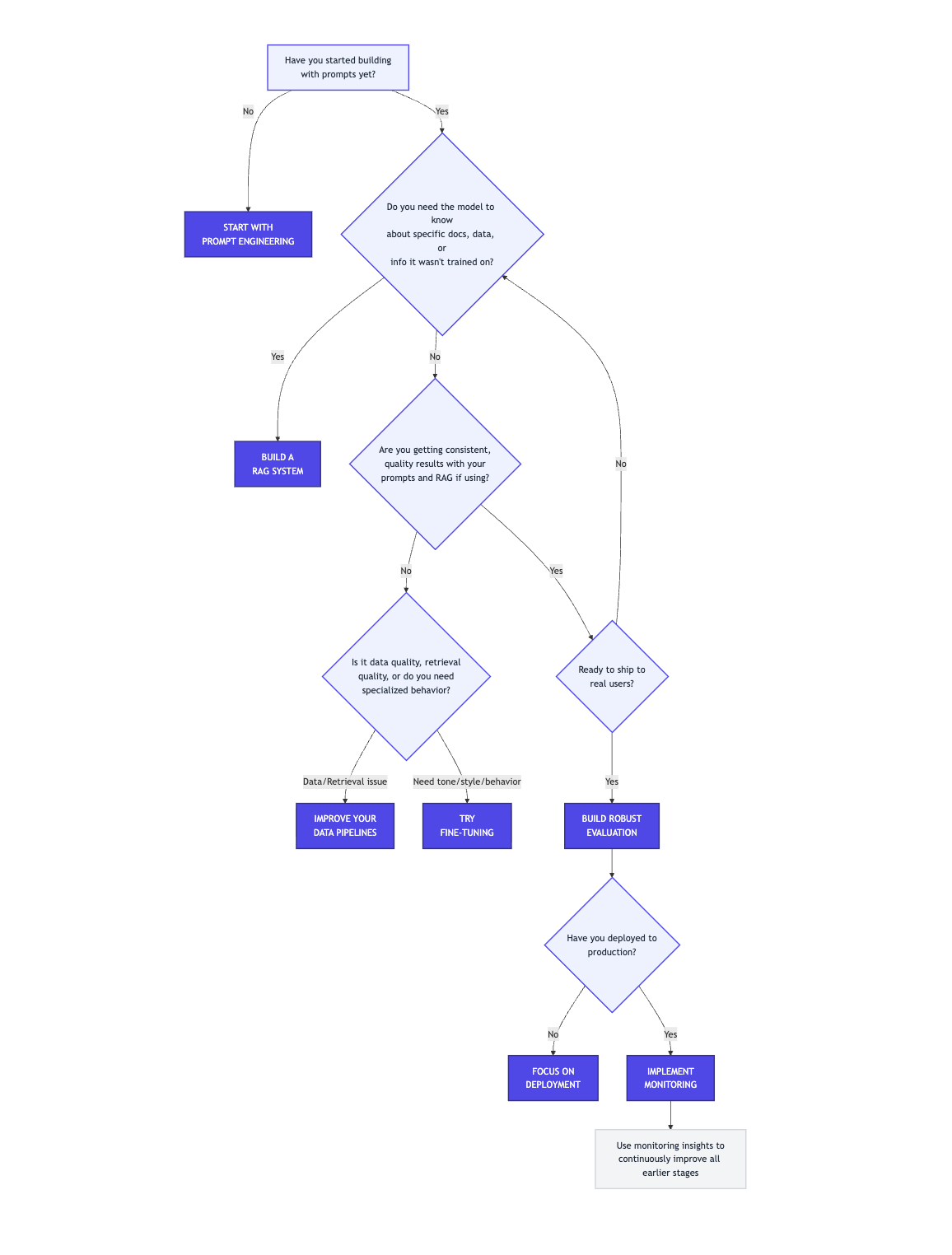
These practices aren’t a checklist to complete - they’re tools in your belt. The best builders know which tool to grab for which job. And here’s the secret: most production LLM apps use prompt engineering + RAG + monitoring. That’s it. Fine-tuning and custom training are for specific optimization scenarios, not starting points.
It is useful to keep this map in mind.
Now go build something great.
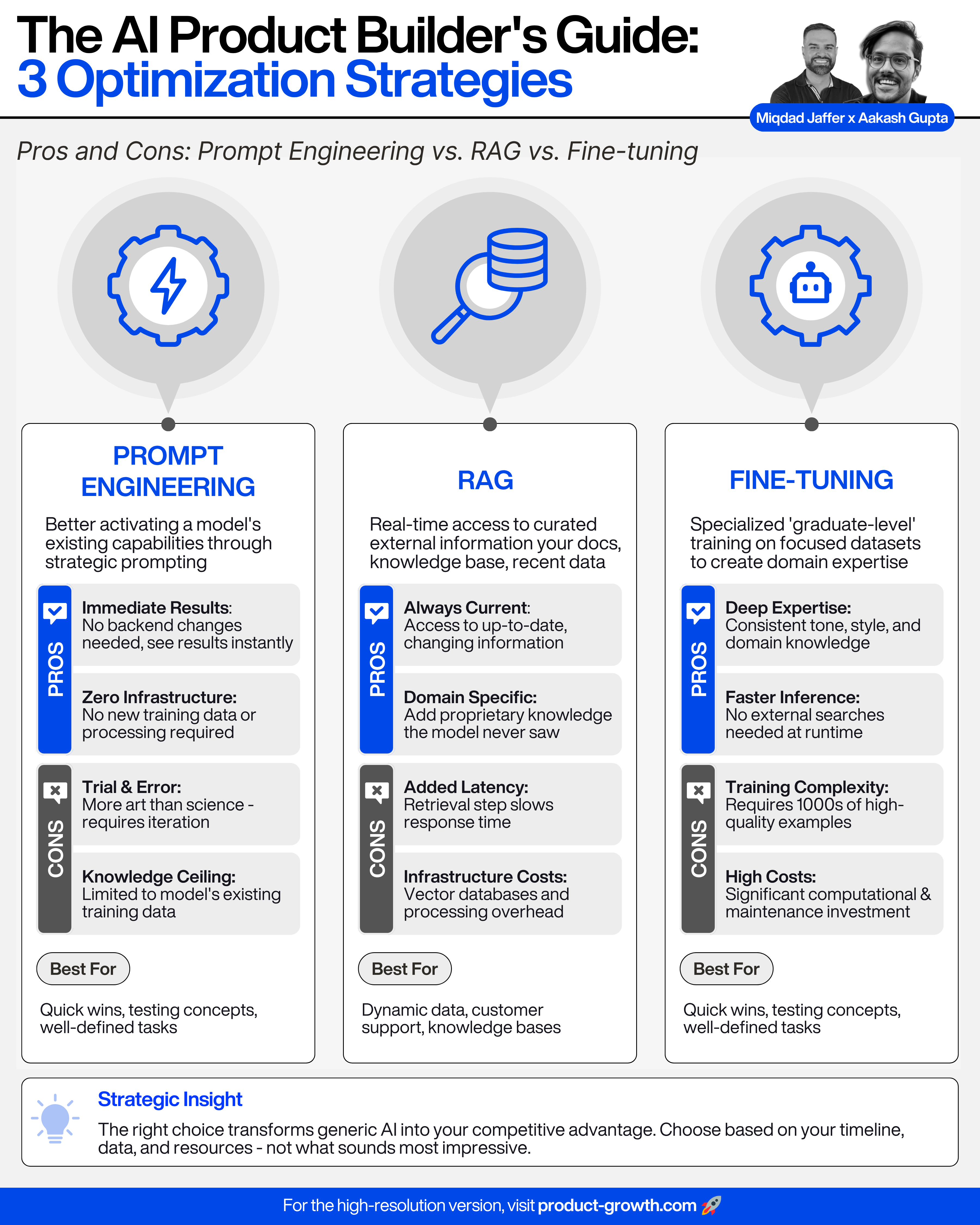
BONUS: I love this comparison chart from Product Growth:

Evolving the Newsletter
This newsletter is more than updates - it is our shared notebook. I want it to reflect what you find most valuable: insights, playbooks, diagrams, or maybe even member spotlights.
👉 Drop me a note, comment, or share your suggestion anytime.
Your feedback will shape how this evolves.
Found this useful? Ask your friends to join.
We have so much planned for the community - can’t wait to share more soon.