
The Evaluation Graph: Why Your AI Pipelines Are Lying to You
This week: the Evaluation Graph - and why the shape of your eval matters more than the score. Your system is a graph. Your evaluations are pipelines. That gap is where production failures live.

Here is a pattern I have seen more times than I can count.
A team deploys an AI system into production. It passes every evaluation they ran. Accuracy looked good. The stakeholder demo went well. The pilot was declared a success. Three months later, the system is quietly shelved because the outputs no longer make sense - or worse, they never did, and nobody caught it until real users started complaining.
When I dig into what went wrong, I often find the shape of the evaluation resulting in low quality agentic decisions.
The teams running linear eval pipelines - input goes in, score comes out - are measuring a snapshot of a moment. They are not measuring how their system behaves as context shifts, as data drifts, as agents hand off to other agents, as the real world does what the real world always does. They are measuring a straight line. Their system is a graph.
That mismatch is why so many AI evaluations feel thorough and turn out to be worthless.
Pipelines vs Graphs
The word ‘pipeline’ is everywhere in AI engineering. Data pipelines, inference pipelines, eval pipelines. We’ve adopted it as the default mental model for how AI systems work.
And for a lot of data engineering, it’s correct. Data flows in one direction. You extract, you transform, you load. A pipeline is a clean metaphor because data really does flow like water through a pipe.
But AI systems in production - especially multi-agent systems, RAG architectures, and anything that has to maintain context across multiple turns or tool calls - do not behave like pipelines. They behave like graphs. There are loops. There are conditional branches. There are nodes that depend on the state of other nodes that were resolved two steps earlier. Context that was established at step one can poison or distort the output at step seven.
When you evaluate a graph as if it were a pipeline, you get a false sense of confidence. You test the happy path. You test the input-output pair. You miss the edges. You miss the feedback loops. You miss the context that has been accumulating and silently corrupting your system’s reasoning.
I’ve started calling this context drift - the phenomenon where a system’s outputs because the context it’s operating in has shifted in ways your evaluations weren’t designed to detect. A pipeline eval can’t catch context drift. Only a graph-shaped evaluation can.
What is an Evaluation Graph?
The Evaluation Graph is not a tool or a framework you install. It’s a mental model - a different way of thinking about what you’re actually evaluating and when.
In a pipeline eval, you define a set of test cases, run your system against them, and score the outputs. Done. Repeatable. Clean.
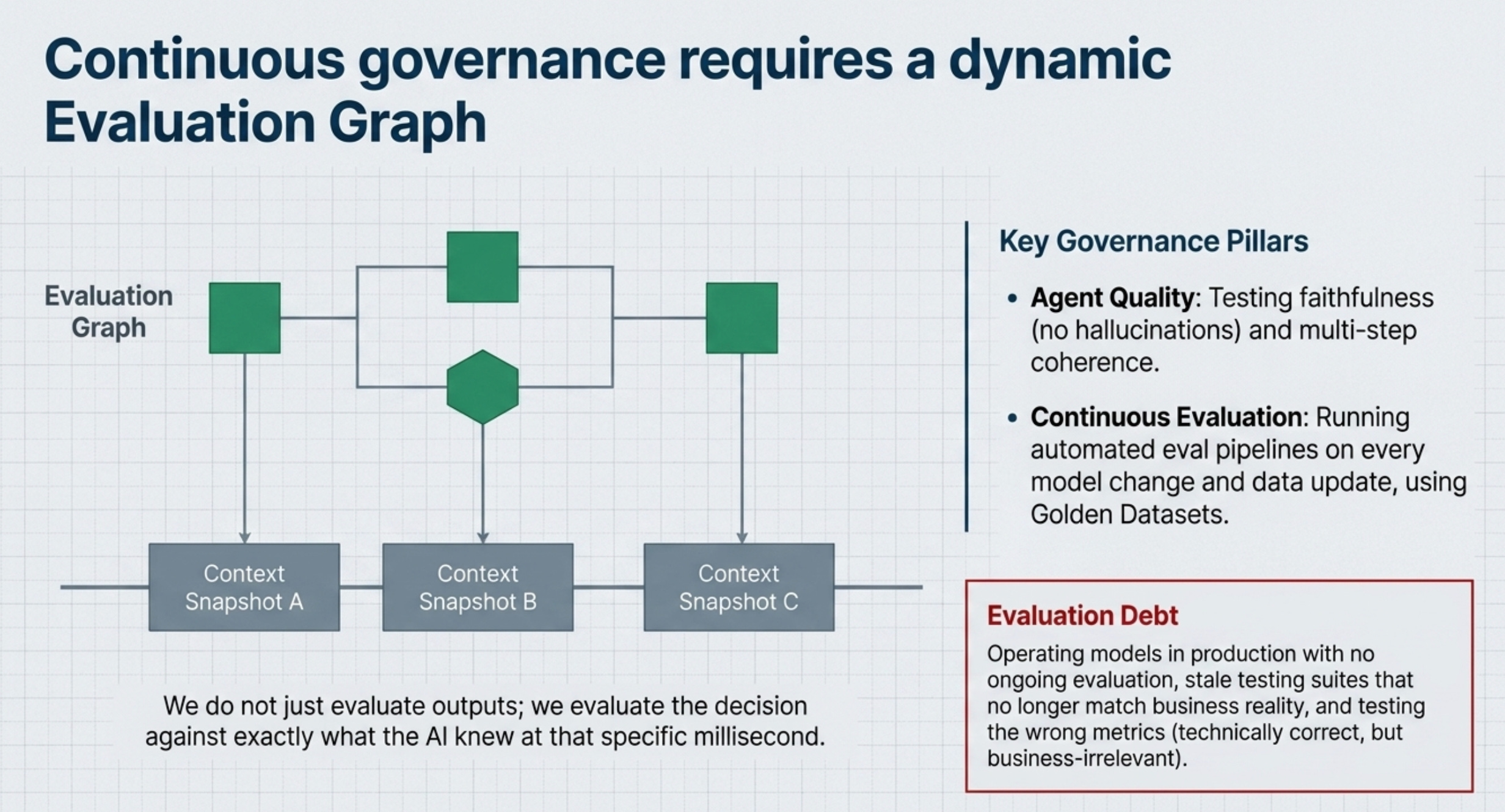
In an evaluation graph, you map out the nodes of your system - the points where decisions are made, where context is retrieved, where agents hand off to each other, where state is read or written - and you evaluate at each node, not just at the final output.
Here is what that changes in practice.
First, you gain localised failure detection. When a pipeline eval fails, you know something went wrong. You don’t know where. When a graph eval fails, you know exactly which node broke down - was it the retrieval? The reranker? The summarisation step? The router that decided which agent to call? You can fix what’s actually broken instead of rerunning the whole system hoping for different results.
Second, you can evaluate context propagation. I have seen this skipped many times. It’s not enough to evaluate whether each node produces a good output given its input. You need to evaluate whether the context being passed between nodes is coherent, relevant, and not accumulating noise. I’ve seen systems where individual components all scored above 90% in isolation, but the system as a whole produced nonsense because each node was passing slightly degraded context to the next one. No pipeline eval would catch that.
Third, you can evaluate decision boundaries. Multi-agent systems have routing logic - conditions that decide which agent runs next, or whether to escalate, or whether to call a tool. These decision boundaries are often the most fragile part of a production AI system, and they’re almost never tested explicitly. In an evaluation graph, they are nodes. They get evaluated just like everything else.
How to Build One
Starting with the evaluation graph doesn’t require you to throw away your existing evals. It requires you to extend them in a specific direction.
The first step is decomposition. Draw out your system - literally, on a whiteboard or in a diagram - and identify every point where a meaningful decision is made or meaningful state changes. Each of those points is a node. Each connection between nodes is an edge. What you’re drawing is the evaluation graph. Most teams are surprised by how many nodes they find that they’ve never evaluated.
The second step is context mapping. For each edge in the graph, define what context is being passed from one node to the next. What does the downstream node need to function correctly? What could the upstream node pass that would corrupt the downstream output? These become your edge-level test cases - not just input-output pairs, but context-propagation scenarios.
The third step is failure mode enumeration. For each node, ask: what does this node look like when it’s failing quietly? Not failing loudly - that’s easy to catch. Quiet failures are the dangerous ones. A retrieval node that returns plausible but wrong documents. A router that sends requests to the wrong agent 15% of the time. A summarisation step that subtly omits the most important information. These failure modes need to be in your evaluation suite explicitly. If they’re not, you won’t find them until a user does.
The fourth step, and this is where graph-shaped evaluation really separates from pipeline evaluation is composing your node-level evals into end-to-end scenarios that test the interaction effects. Not just ‘does node A work’ and ‘does node B work’, but ‘when node A produces this class of output, does node B degrade in a predictable way’. The interactions between nodes are often where production AI systems fail.
This Needs a Shift in Mindset
The teams that build AI systems that hold up in production are building the most rigorous evaluation infrastructure. And rigorous evaluation infrastructure starts with a simple question: is my evaluation shaped like my system?
If your system is a graph and your evaluations are pipelines, you have a gap. That gap is where production failures live.
The evaluation graph is not a perfect solution - no evaluation framework is. Context still drifts in ways you won’t anticipate. Failure modes you didn’t enumerate will still appear. But it gets you structurally closer to what’s actually happening in your system, and that’s the difference between catching problems in staging and catching them after a customer has seen them.
This is one of the core concepts I’m currently working on. If it resonates with what you’re seeing in your own work, I’d genuinely like to hear about it. Hit reply and tell me what you see. The patterns you share inform what I write next.
Talk soon,
Sandi
👉 I wrote more about the Eval Graphs in my article on Atlan’s community substack.

P.S. If you’re new here - welcome 🎉. AgentBuild is a community of practitioners working through the real challenges of getting AI into production inside large organisations. Every week I share practical, grounded thinking from the people doing this work at the sharp end. The goal is never theory - it’s always: what can you use Monday morning.
Ask your friends to join.
More valuable content coming your way.