
The Hidden Cost of ‘Good Enough’ AI
Learn how high-accuracy AI still fails - and why most teams never spot the warning signs until it’s too late. Here’s how to check before it blows up.

Hey AgentBuilders,
Customers often show me their dashboards with prefect metrics for their AI performance. You’ve probably seen such dashboards.
High accuracy. Low error rates. But, their customers are not satisfied.
Imagine how many time you literally shouted to a chatbot -
“Pass me to a human, ffs!“

70 % to 85 % of AI initiatives fail to deliver meaningful business outcomes. Research shows that more than 40 % of companies abandon most of their AI projects before production. While your test-set accuracy might hit 96%, what if the model simply replicated yesterday’s bad behaviour instead of solving tomorrow’s problem?
Your customers feel the pain long before your AI metrics do. The hidden cost of ‘good enough’ AI is often your customers walking out the door.
Today I answer the following questions that often come up in my meetings:
Why do models with high accuracy still lead to customer complaints?
How do I know if the problem is the model or our business definitions?
How do I fix data contradictions before they poison every downstream system?
How do I extract the real rules our teams use (not the ones we think they use)?
How do I build an evaluation system that catches AI failures before customers notice?
Earlier this year, a fintech company showed me their fraud detection system. Six months of work. $100K invested. 96% accuracy on their test set.
“The metrics look good, but customer satisfaction has not improved. Recently we are hearing more complaints ” the VP of Engineering told me.
I worked with his data scientists. We pulled up a transaction:
$127 purchase from a returning customer in Glasgow. The AI flagged it as fraud.
“Why?” I asked.
The data scientist pulled up the model’s feature importances.
“High confidence on velocity patterns and device fingerprint mismatch.”
“Right, but why is that fraud?”
Silence.
We dug into the training data. Turned out, their fraud team had been blocking transactions whenever they saw any red flags - not because they were actually fraud, but because blocking was safer than approving.
The AI learned caution, not accuracy.
The model was 96% accurate at predicting what the fraud team did. It had no idea what fraud actually was.
This is what happens when you optimize AI for performance without ever defining what you’re performing for.
Everyone Wants AI to Optimize Something
Walk into any company building AI and ask: “What are you optimizing for?”
You’ll get answers like “accuracy” or “user satisfaction” or “efficiency.”
Ask the next question: “How do you measure that?” and you get conflicting answers.
It is always because the teams never agreed on what good looks like.
You can’t automate a decision that was never defined. When the AI underperforms, it gets blamed for what’s really a lack of clarity.
But here’s the part I lhave learnt through experience: forcing that clarity is often the most valuable part of building AI.
Once teams are asked to define the decision they want to automate - its rules, trade-offs, exceptions - they realize AI isn’t a magic wand. It’s a mirror.
It reflects every place the organization is vague, inconsistent, or indecisive.
The Three Walls Every AI Project Hits
I’ve watched dozens of AI projects launch with great fanfare and quietly fail within six months. Not because the models were bad. Because three foundational problems were never solved:
Data Integrity: Your data sources contradict each other
Decision Clarity: Your business never agreed on the rules
Evaluation Architecture: You can’t tell if it’s working

These aren’t separate problems. They’re adjacent. When you fix one, and the others start to align.
Most consultants will tell you this requires a multi-year transformation program.
It doesn’t. You need three foundations you can start building immediately.
1. Data Integrity: The Fight You’ve Been Avoiding
Forget “clean data.” That’s an outcome, not a strategy.
Data integrity means one source of truth per domain - defined, owned, and documented.
Here’s how the problem shows up:
I was working with a SaaS company trying to predict churn. They’d trained a model on two years of data. 67% accuracy. Couldn’t beat it no matter what they tried.
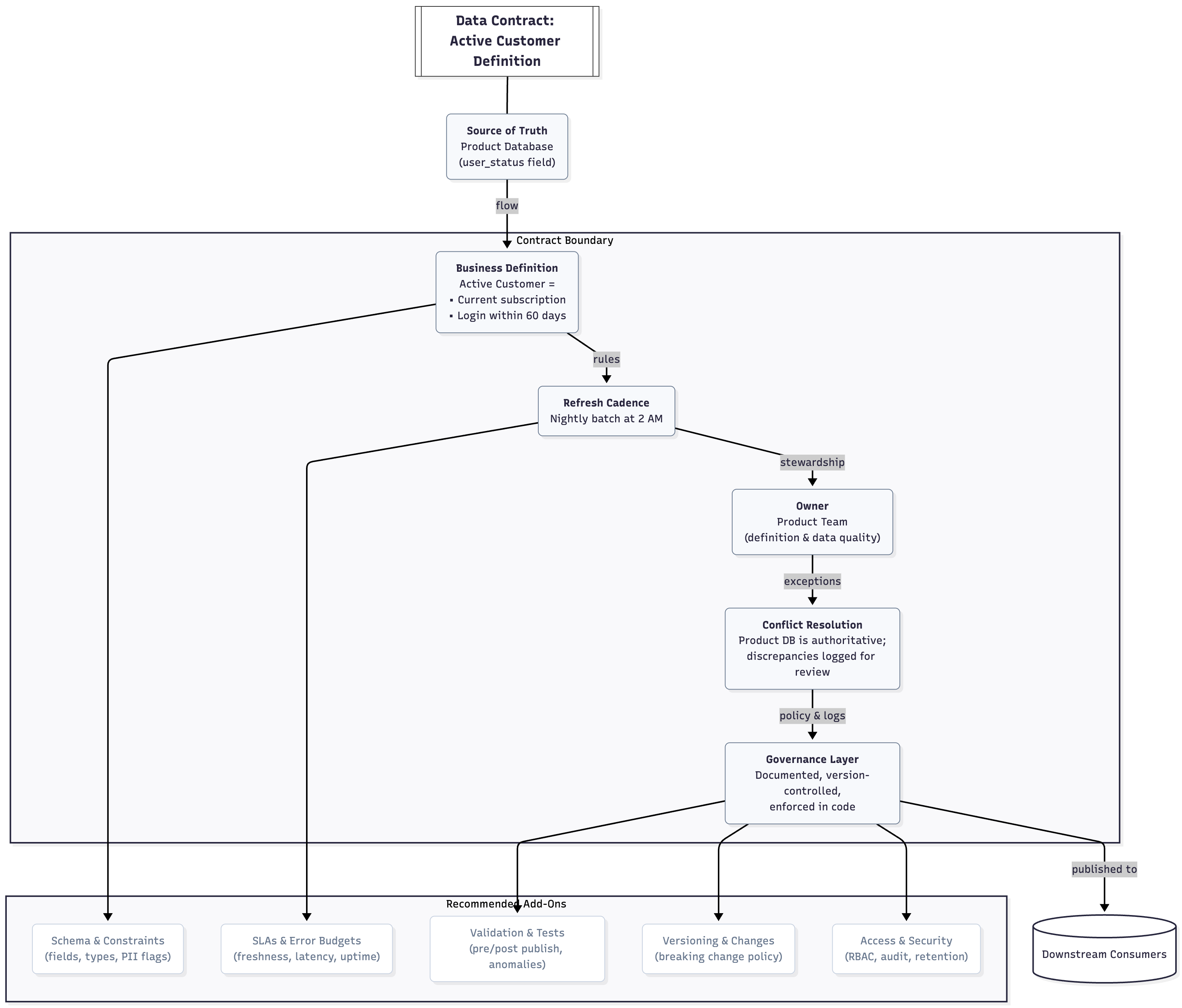
I asked them to define “active customer”
Sales said: “Anyone who’s purchased in the last 90 days.”
Finance said: “Anyone with a current subscription.”
Product said: “Anyone who’s logged in this month.”
Their training data was pulling from all three sources. The model was trying to predict churn using three different, contradictory definitions of “customer.”
The model wasn’t confused. The business was.
We got the three teams in a room. It took four hours and got heated. Finance didn’t trust product’s login data (”too easy to game”). Sales didn’t care about logins (”they’re paying, aren’t they?”). Product argued subscriptions didn’t reflect actual usage.
Eventually, they agreed:
Source of truth: Product database (user_status field)
Definition: Active = current subscription AND login within 60 days
Owner: Product team owns the definition and the data
Refresh cadence: Nightly batch at 2 AM
Conflict resolution: Product DB wins; discrepancies logged for review
They documented it. Versioned it. Enforced it in code.
Retrained the model on clean, consistent data.
Accuracy jumped above 85%.
The model didn’t change. The input finally meant the same thing to everyone.
👉 Action: Start small. Pick one critical data domain. Get the stakeholders in a room. Write down:
What’s the source of truth?
Who owns it?
How often does it refresh?
What happens on conflict?
That’s your first data contract. This will take days, possibly weeks. It’s supposed to. If you finish in an afternoon, you didn’t actually resolve anything.
2. Decision Clarity: Your Unwritten Rules
Before you let AI make a decision, document how humans make it today.
I worked with a B2B SaaS company that wanted to automate their sales qualification process. Lead comes in, AI scores it, passes it to sales or rejects it.
Simple, right?
I met their sales team multiple times for two weeks - just to understand how they work.
Turned out, they had rules everyone knew, but no one had written down:
Leads from Fortune 500 companies always get a call, even if the form is incomplete
If the email domain is @gmail.com and the company field says “Enterprise Corp,” reject it (probably fake)
If someone mentions a competitor by name, flag it to senior sales
If the lead is from a country where we have no payment processor, politely decline
None of this was in the CRM. It was all in the heads of three senior sales reps who’d been there for years.
We spent two weeks extracting these rules. Tested them against six months of historical decisions. About 80% held up. The other 20% were inconsistent - even the sales team disagreed on what to do.
👉 That inconsistency? That’s what the AI would’ve learned.
We documented the rules. Built a decision tree. Ran it past legal and sales leadership. Got everyone to sign off.
When we finally built the AI, it had a clear target. It wasn’t inventing policy. It was executing agreed-upon rules at scale.
The exercise revealed something serious: they didn’t need AI for 60% of the decisions. The rules were simple enough to codify as logic. AI only added value on the fuzzy 40% - the judgment calls where patterns mattered.
👉 Your turn: Pick one decision your AI will make.
Write down how humans make it today.
Include the edge cases.
The exceptions.
The “it depends” scenarios.
If you can’t write it down, your AI will invent something. And you won’t like what it invents.
3. Evaluation Architecture: The System No One Builds
This is where amateurs stop and professionals start.
I’ve seen it happen a dozen times:
Month 1: Launch the AI. 95% accuracy on test data. Celebrations.
Month 2: A few user complaints. “Early adopters are picky.”
Month 3: The AI starts behaving differently. No one notices because no one’s checking.
Month 4: A customer escalation reveals the model has been making bad decisions for weeks.
Month 5: Emergency patches in production. No one knows what broke or when.
AI isn’t a static product. It’s a living system in a changing world. Data drifts. Users evolve. Edge cases emerge. Without evaluation, you’re flying blind.
👉 Here’s what works:
Build the evaluation system before you build the AI.

One company I advised did this right. Before writing any model code, they built a “golden set”:
300 real examples from production (mix of easy wins, edge cases, known failures)
Each example labeled with the correct decision and why it was correct
Included adversarial cases: things that looked like fraud but weren’t, things that looked legitimate but were suspicious
They version-controlled this set alongside their code.
Every change - new prompt, new model version, new training data - ran through the golden set automatically in CI/CD.
They tracked:
Overall accuracy (did it match human decisions?)
Precision on edge cases (did it catch the tricky ones?)
Consistency over time (did performance degrade?)
When a human overrode the AI in production, that case got reviewed. If it was interesting, it went into the golden set.
The golden set became a living organism. It learned as the AI learned.
Six months later, their model was still performing within 2% of launch accuracy. Most companies see 10-15% degradation in that timeframe.
And the importnat distinction was the fact that they knew when things broke, because they were checking every day.
Start with 300-500 examples (there is no good number) Real cases where you know the right answer. Document why each is labeled that way. Run every change through this set before it touches production.
Without this, your AI will degrade silently. You’ll only notice when users start complaining.
The Real Maturity Test
Here’s how you know if you’re ready for AI:
Ask your team: “If we turned off the AI tomorrow, could you codify the decision it’s making as a flowchart?”
If the answer is no, you’re not doing AI.
You’re outsourcing decisions to a black box and hoping for the best.
If the answer is yes, but the flowchart contradicts itself in five places - congratulations, you just discovered why your AI is underperforming.
The better AI systems aren’t the ones with the most sophisticated models. They’re the ones built by teams who knew exactly what they wanted to automate. Most teams chase better models. The ones that succeed build better foundations.
They stop asking “Can AI solve this?” and start asking:
What decision are we actually making?
Do we agree on what “correct” looks like?
How will we know if it’s working?
AI doesn’t transform a business. It reveals how untransformed the business already is.
The companies that succeed with AI aren’t the ones with the best data scientists. They’re the ones who did the unglamorous work of defining what “correct” actually means.
That work isn’t sexy. It doesn’t make conference talks. But it’s the difference between AI that ships and AI that lasts.
Final Thoughts
If you’re building AI systems and keep hitting these walls, you’re not alone. The gap between “we launched it” and “it’s actually working” is wider than most people admit.
The teams I see winning aren’t using better models. They’re doing the hard work of alignment: getting stakeholders to agree, documenting the unwritten rules, and building evaluation into the architecture from day one.
Start there. Everything else gets easier.
Evolving the Newsletter
This newsletter is more than updates - it is our shared notebook. I want it to reflect what you find most valuable: insights, playbooks, diagrams, or maybe even member spotlights.
👉 Drop me a note, comment, or share your suggestion anytime.
Your feedback will shape how this evolves.
Found this useful? Ask your friends to join.
We have so much planned for the community - can’t wait to share more soon.