
Why Agent-to-Agent Communication Fails - How to Design for Failure
This week: Agent communication is a major problem in multi-agent systems. What are the common failure modes, how to design for them, and key lessons I have learnt.

Hey everyone,
If you’ve been building AI applications recently, you’ve likely noticed a massive architectural shift. We are moving away from monolithic, “do-everything” prompts and toward multi-agent systems. It’s an elegant idea: instead of one massive language model struggling to write code, test it, and document it simultaneously, you spin up specialized agents - a Coder, a Tester, and a Writer - and have them collaborate.
But as teams push these systems into production, they are hitting a wall. Having five smart agents does not automatically equal one smart system.
The industry is quickly learning a hard lesson: orchestration is an understood problem, and communication reliability is the actual bottleneck . You can easily instantiate ten agents using frameworks like LangGraph, AutoGen, or CrewAI. But getting them to talk to each other reliably without hallucinating payloads, dropping context, or getting stuck in infinite loops is where the real engineering happens.
Let’s break down the first principles of agent communication, look at how they fail in production, and explore how modern production systems are solving these exact problems.
The First Principles of Agent Communication
At its core, getting agents to collaborate requires the same fundamentals as distributed computing, but with a chaotic twist: the “nodes” in this network are non-deterministic text engines.
1. Message Passing
Principle: Message passing is the transfer of information from one node to another. When Agent A finishes its job, it must hand off a payload to Agent B to trigger the next step.
Failure Mode: The Hallucinated Payload.
Example: A Data Extraction Agent is told to pull a user’s ID and pass it to a Database Agent. Instead of passing
12345, the agent passes, “Here is the user ID you requested: 12345.” The Database Agent expects an integer, receives a conversational string, and crashes.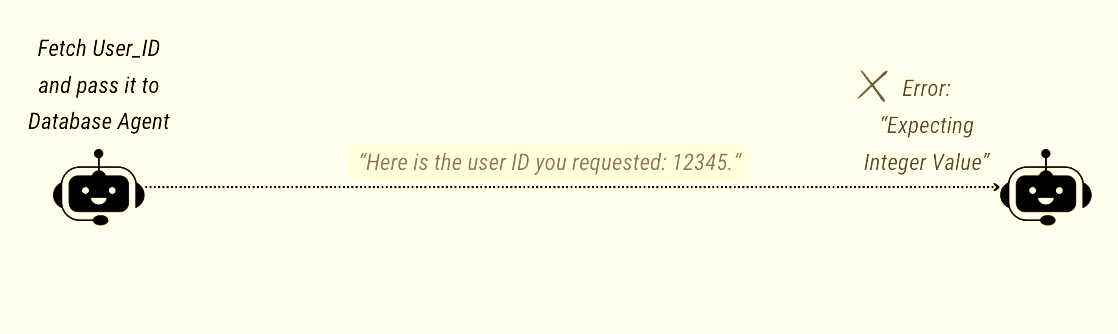
Agents communicating in natural langugage are prone to errors Why it happens: LLMs are fine-tuned to be helpful conversationalists, not strict state machines. Without hard constraints, they inject pleasantries and markdown formatting into their outputs, corrupting the message payload.

2. Protocols and Interfaces - H2A, A2C, A2A
Principle: Protocols dictate the rules of engagement. In modern agentic systems, we categorize these interfaces into three distinct buckets:
H2A (Human-to-Agent): Conversational, unstructured, and forgiving (e.g., ChatGPT).
A2C (Agent-to-Computer): Rigid and deterministic. The industry standard here is the Model Context Protocol (MCP). Introduced by Anthropic in late 2024 and now hosted under the Linux Foundation, MCP standardizes how agents securely connect to external tools, IDEs, and databases.
A2A (Agent-to-Agent): Peer-to-peer communication between two non-deterministic models. This is historically the most fragmented layer, but the industry recently coalesced around the Agent-to-Agent (A2A) Protocol. Originally released by Google in April 2025 and unified with IBM’s Agent Communication Protocol (ACP), A2A is now a Linux Foundation open standard for cross-framework agent discovery and task delegation over HTTP and JSON-RPC.
Failure Mode: Interface Confusion.
Example: A developer uses MCP to perfectly connect a Research Agent to a PostgreSQL database (A2C). But when the Research Agent hands the data to a Writer Agent (A2A), the developer lets them communicate in conversational English. The Writer Agent misinterprets the unstructured text and hallucinates missing facts.
Why it happens: Developers often treat A2A communication like H2A communication. Unless you enforce machine-readable protocols for peer-to-agent handoffs, conversational drift will inevitably break your architecture.
3. Shared Context and State
Principle: Agents need a shared understanding of the environment, current progress, and available data to collaborate effectively.
Failure Mode: Context Desynchronization.
Real-World Example: A Researcher Agent analyzes a 50-page PDF and passes a brief outline to a Writer Agent. The Writer tries to draft the article but fabricates details because it lacks access to the source material.
Why it happens: Context windows are expensive. To save tokens and latency, builders often restrict the context passed downstream. This creates asymmetric information - Agent A knows something Agent B doesn’t, leading to poor decisions.
4. Intent Alignment
Principle: Every agent in the chain must understand the overarching goal of the user, not just its localized sub-task, to ensure the final output is cohesive.
Failure Mode: The Telephone Game.
Example: A user asks for a “brief, humorous summary of the latest AI news.” The Manager Agent passes the news to the Summarizer Agent but forgets to include the “humorous” instruction. The Summarizer writes a dry academic brief.
Why it happens: Information decays across hops. When breaking a complex prompt into smaller agentic tasks, the nuance of the original user prompt is easily lost in translation.

Reference read: https://arxiv.org/pdf/2407.04503

5. Memory and Feedback Loops
Principle: When Agent B rejects Agent A’s work, Agent A needs memory of the failure and the ability to correct itself without repeating the exact same mistake.
Failure Mode: The Infinite Death Spiral.
Example: A Coding Agent writes a Python script. The Execution Agent runs it, encounters a
SyntaxError, and passes the error back. The Coder apologizes, generates the exact same code, and sends it back. They repeat this loop 50 times until the API budget is drained.Why it happens: LLMs are highly sensitive to their immediate context. If the feedback isn’t explicit, or if the model’s internal weights heavily favor a flawed syntax pattern, it will deterministically generate the same wrong answer.
How To Solve This - Patterns That Are Working
Building reliable multi-agent systems requires shifting your mindset from “prompt engineering” to “protocol engineering.” Here is how top-tier engineering teams are building resilience into their agent networks.
1. Enforce Structured Outputs (a.k.a Strict Schemas)
Never let agents talk to each other in free-text prose if they are exchanging data. Treat agent communication exactly like an API. Use tools like OpenAI’s Structured Outputs, Pydantic, or standard Python libraries like instructor to enforce JSON schemas. If Agent A needs to pass an ID to Agent B, structurally guarantee that the output is only a valid JSON object matching your exact schema.

2. Adopt Standardized Protocols
Stop reinventing the wheel for tool use and communication. Implement MCP for all A2C interactions to securely connect your agents to external systems. For A2A interactions, adopt the A2A Protocol to standardize payload structures instead of injecting variables into conversational prompt templates. Leveraging these standards ensures your agents can operate reliably across different platforms and enterprise environments.
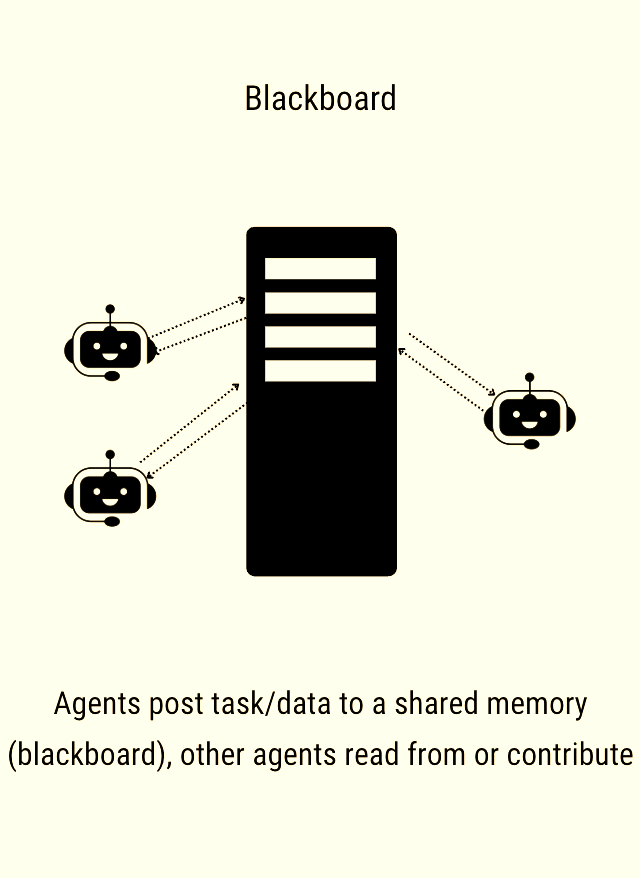
3. Centralize State (The “Blackboard” Pattern)
Instead of passing massive context back and forth between agents like a hot potato, use a centralized state mechanism. In graph-based frameworks like LangGraph, all agents read from and write to a single, shared state object or “blackboard.” This ensures no agent is operating on outdated or asymmetric information.
4. Implement Observability and Tracing
When a multi-agent system fails, it fails silently and weirdly. You cannot debug these systems with standard print statements. You need dedicated LLM observability platforms like LangSmith, Langfuse, or MLflow 3.0 to trace the exact input, output, and execution path of every single node. If the Telephone Game happens, you need to see exactly which agent dropped the context.
5. Defensive Programming: Retries and HITL
Expect agents to fail. Wrap inter-agent communication in standard retry logic with programmatic guardrails (like NVIDIA’s NeMo Guardrails). If Agent A sends malformed data, catch the error programmatically and format it into a rigid prompt to force a correction. For critical workflows like writing to a production database (or deleting production databases) - enforce a Human-in-the-Loop (HITL) pause. Let the system wait for human approval before executing destructive actions.
Lessons Learnt
Treat agents like microservices: A2A communication should mirror microservice architecture. Define rigid, structured API contracts for every handoff and validate payloads before they reach the next node.
Embrace MCP and emerging standards: Separate your A2C (tool use) from your A2A (agent coordination). Use standardized open-source protocols like MCP and A2A to offload the complexity of system integrations so your agents can focus on logic.
Cap your feedback loops: Always implement hard limits on iterative loops. If agents go back-and-forth more than three times without success, throw an exception and escalate to a human or a deterministic fallback script.
Persist the global goal: Inject the original user intent into the system prompt of every agent in the pipeline. Do not assume intent will survive passing through three different LLM nodes.
Multi-agent architectures are the future of complex AI applications, but they require rigorous distributed systems engineering. By enforcing strict protocols and shared state, you can stop the silent failures and build agentic systems that actually work in the real world.
See It In Action
I’ve talked about the common patterns and failure modes of multi-agent orchestration and how to design for them in this video. Have a look.
As always your comments and feedback are welcome. Please share your experience and thoughts.
Thanks,
Sandi.
P.S. If you’re new here - welcome 🎉. AgentBuild is a community of practitioners working through the real challenges of getting AI into production inside large organisations. Every week I share practical, grounded thinking from the people doing this work at the sharp end. The goal is never theory - it’s always: what can you use Monday morning.
Ask your friends to join.
More valuable content coming your way.
Designing for failure between agents is the part teams skip. Most setups assume the receiving agent reads the message the way the sender meant it. Half the bugs I’ve seen come from one agent confidently passing context the next one silently misinterprets. Building the expected-failure path first changes the whole architecture.
Designing for failure between agents is the part teams skip. Most setups assume the receiving agent reads the message the way the sender meant it. Half the bugs I’ve seen come from one agent confidently passing context the next one silently misinterprets. Building the expected-failure path first changes the whole architecture.