
Context Graph vs Evaluation Graph
Today: What is the difference between a context graph and and an evaluation graph - why both are important - and what questions should you ask today.

Picture yourself in a restaurant where the menu changes daily. You order “the soup.” The chef makes whatever’s on today’s board. After few hours you’re not feeling great, and you go back and ask what was in the soup. The waiter pulls your order slip. It says “soup.” And yes, the kitchen did make the soup. But nobody wrote down which soup, made with what, sourced from where, signed off by which supplier. Nobody wrote any of that down next to the order. The order slip is reproducible - they can print it out again and it would say “soup“. But they cannot prove what was in the soup that could have made you sick.
That’s where most AI teams sit right now. Versioning the order slip beautifully. Not tracking what was actually in the bowl.
The fix for this isn’t a better model log. It’s a different structure that sits alongside it - what I’ve been calling an evaluation graph. Every time the AI runs, it takes a hashed, timestamped snapshot of every governance artefact in force at that exact moment: the glossary term version, the policy version, the dataset certification. So six months later, when the definition has moved from version 2.3 to 2.4, you’re not reconstructing anything. You look it up. The snapshot tells you exactly which soup the kitchen made that day, and who signed off on the recipe.
Evaluation Graph vs Context Graph
People keep confusing this with a context graph, which is genuinely a different thing. What the difference?
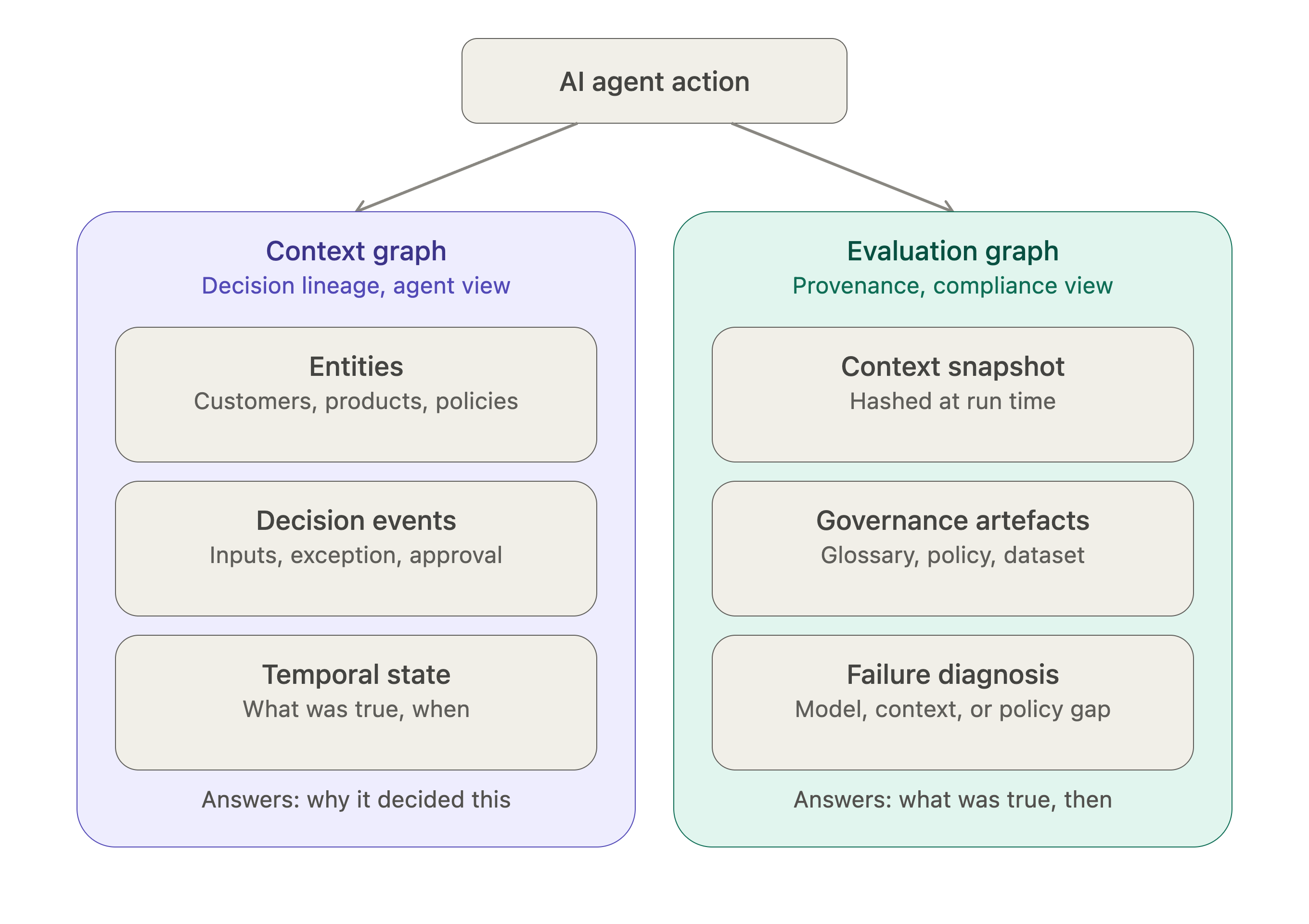
The evaluation graph is the receipt that proves what was actually served. It records: today’s menu version, which supplier the tomatoes came from, which health certification was active, what time the dish left the kitchen. Six months later, if someone asks “was this dish safe and compliant on that day,” you don’t guess, you pull the receipt and know exactly which version of “today’s soup” this was, signed off by whom. That’s provenance. It’s not about why the waiter brought you soup. It’s about proving what was true in the kitchen at that exact moment.
The context graph is the waiter’s reasoning for why you got soup at all. Maybe you said “I’m not very hungry,” the waiter remembered you’re allergic to shellfish from last visit, saw the bisque was off the board today anyway, and recommended the soup as the lightest, safest option. That whole chain - your stated preference, the remembered allergy, the menu constraint, the final recommendation is the decision lineage. If you later ask “why did you suggest soup,” the context graph is what lets the restaurant reconstruct that reasoning instead of shrugging and saying “the waiter just did.”
So: same dish, two completely different questions.
Evaluation graph: “Prove what was actually in the bowl, and that it met standards, on that specific day.” (Provenance, was the input governed correctly?)
Context graph: “Explain why the waiter chose this for you specifically.” (Lineage, why did the agent decide what it decided?)
A restaurant or a bank can have perfect receipts and a clueless waiter. Or a brilliant waiter with no receipts to back up a regulator's question. You need both, and they're solving for different failure modes.
What this looks like technically
Strip away the restaurant for a moment. Here’s the conceptual shape of both graphs, and the one thing that ties them together.
A context graph is built from three kinds of nodes.
Entities: the customers, products, policies, and people your business already has some version of in a knowledge graph.
Decision events: each time an agent or a human makes a choice, that choice becomes its own node, carrying the inputs, the policy applied, any exception made, and the outcome.
Temporal state: because the graph needs to know not just what’s true now, but what was true at the moment the decision happened. Sarah was a Director in May; she’s a VP today. The graph needs to know which one mattered when.
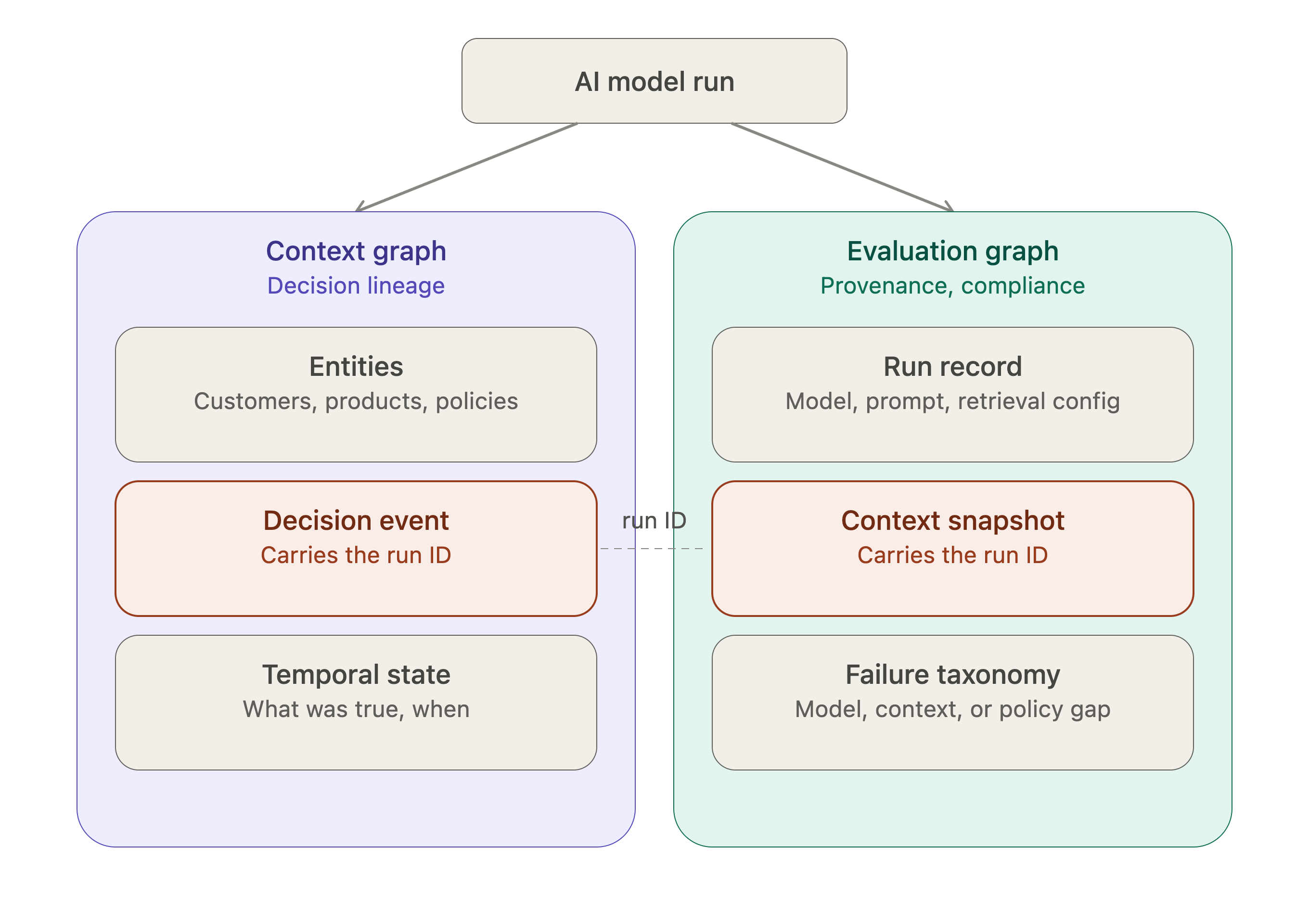
An evaluation graph is built differently, because it’s answering a different question. Its core node is a context snapshot taken at the exact moment a model runs, hashed and timestamped, pointing to the specific versions of every governance artefact in force at that instant: the glossary definition, the policy version, the dataset certification. Alongside that sits the run itself - the model version, the prompt template, the retrieval configuration, and a failure taxonomy that lets you diagnose, after the fact, whether a wrong answer was a model failure, a context failure, or a policy gap.
The two graphs aren’t separate systems sitting in isolation. They connect through one shared reference: the run, or the decision event itself. Every decision event in the context graph that involved a model call can carry a pointer to the evaluation graph’s snapshot for that exact run.
When someone asks “why did the agent decide this,” you walk the context graph. When someone asks “what was governing the system when it decided that,” you follow the same run ID into the evaluation graph and pull the snapshot. One graph for the reasoning, one graph for the proof, joined at the single point where the AI actually executed.
Practically, this doesn’t require building either graph from scratch on a green field. If you’re already running something like MLflow or Databricks AI Agent Evaluation, the run node is just a thin wrapper around the run ID your platform already generates. The context snapshot capture can be a pre-run hook - a lightweight call to your catalog and glossary APIs that resolves the current versions of everything relevant, hashes them, and writes the snapshot before the model executes. The heavier lift is the context graph side, because that one has to live inside the execution path - you can’t capture a decision event you weren’t watching for when it happened.
What I’d actually do about it
These concepts are new and pretty early for many organisations. My advise is to be congnizant and ask questions for every AI build that passes through the architecture team. So, before your next model goes anywhere near a regulated workflow, ask one question out loud in the project meeting: if a regulator asks us to reproduce this exact answer in six months, what’s allowed to change underneath us between now and then?
Then write down every governed artefact that answer depends on. Glossary terms. Policy versions. Dataset certifications. For each one, name who owns it and how often it moves. If you can’t answer that for every item on the list, you don’t have an evaluation graph yet - you have a model log dressed up as proof.
That’s not a backlog item to schedule for next quarter. It’s the difference between “we can rerun the query” and “we can actually explain the decision.”
The Evaluation Graph: Why Your AI Pipelines Are Lying to You

Here is a pattern I have seen more times than I can count.
Where to go next
I’d genuinely like to know what you’re seeing on your side. Has anyone asked your team to reproduce a decision and found the same gap I’m describing? Is this something your governance and AI teams have already wired together, or is it still sitting in the gap between two calendars like it was at the bank above?
Hit reply or drop a comment. Tell me about the patterns you’re seeing, they usually end up shaping what I write next.
Talk soon,
Sandi
P.S. If you’re new here - welcome 🎉. AgentBuild is a community of practitioners working through the real challenges of getting AI into production inside large organisations. Every week I share practical, grounded thinking from the people doing this work at the sharp end. The goal is never theory - it’s always: what can you use Monday morning.
Talk soon,
Sandi.
Ask your friends to join.
More valuable content coming your way.
Thanks for reading agentbuild.ai! Subscribe for free to receive new posts and support my work.
Curious on if this is a new pattern for observability ?