
MCP: What’s Actually Working, What’s Breaking, and How to Do It Right
This week: Honest look at the Model Context Protocol and what history says about where this goes next. A decision tree, an architecture pattern, and several best practices.

This article is too long for email - it might have been truncated. Please read on Substack.
TL;DR
MCP is the right abstraction for standardising tool access across multiple agents, but most teams are deploying it without the governance it needs
Five failure modes keep appearing in regulated environments: hardcoded credentials, no authorisation layer between model and tool, invisible tool calls, server sprawl, and untracked data residency
MCP is not always the right choice. Direct function calling, existing APIs, and async queues are better fits for several common patterns
The fix isn’t complicated: treat MCP servers as infrastructure, instrument every tool call at the boundary, and never let the model be your policy engine
MCP is at that USB moment
Something shifted in 2024. Developers started asking, “can we connect an LLM to our tools?” and then wondering, “how do we do it without building a different integration for every model, every framework, every team?”
These are the questions MCP answers. The Model Context Protocol, originally developed by Anthropic and released in November 2024, and now gaining ground as a de facto standard.
By mid-2025, MCP had moved from research-adjacent to actively deployed. GitHub Copilot, Cursor, Claude, and a growing list of enterprise agent frameworks had either adopted or announced support. The server ecosystem - registries, SDKs in Python and TypeScript, community-contributed connectors for everything from PostgreSQL to Salesforce had expanded fast. Almost every other product has its MCP.

That speed should give you pause.
This is a pattern we’ve seen before. When USB was introduced in 1996, it solved a real problem: a dozen incompatible port types on the back of every PC. It was the right abstraction. And within a few years, “plug and play” had become a running joke because the driver ecosystem moved faster than the discipline around it. Devices connected. Systems crashed. Enterprise IT spent years cleaning up what consumer enthusiasm had shipped. While the protocol was fine, the deployment culture was not.
MCP is at that USB moment. The abstraction is right. The ecosystem is moving faster than the engineering rigour around it. Teams are shipping MCP servers in sprints, demoing them to CTOs, and having them in production eight weeks later. Six months after that, nobody can tell you what tools the agent is calling, the credentials haven’t been rotated since go-live, and there is no audit trail that would survive a compliance review.
The protocol didn’t fail them. The deployment pattern did.
This article is about the difference.
Tool Definition: A Contract with Non-Determinism
The fundamental difference between an MCP tool and a standard API is that it is a contract between a traditional, deterministic backend system and a non-deterministic LLM agent. Standard API engineering assumes a consumer will call a function exactly as documented. Agent tooling requires developers to accept that the model will interpret the description and choose the arguments. This non-deterministic usage is why building for agents requires a higher degree of protective rigor around entitlement, validation, and audit than standard integration patterns.
What MCP gets right?
MCP is solving a real problem, and the core of it is genuinely well-designed.
The integration tax is real, and MCP eliminates it
Before MCP, connecting an agent to a tool meant writing bespoke integration code. Every model had its own function-calling format. Every framework had its own abstraction layer. If you wanted to switch from one agent framework to another, you rebuilt your integrations. If you wanted the same capability accessible across multiple agents, you duplicated the logic and prayed for consistency.
Without a shared protocol, every team builds its own integration in the shape of its own constraints - its available libraries, its preferred auth pattern, its interpretation of what the downstream system needs. The result is integration sprawl that compounds with every new team that touches the same system. MCP breaks that coupling. A single MCP server exposes a set of tools, resources, and prompts under a standardised interface. Any MCP-compatible client regardless of which model or framework it uses, can discover and invoke those tools through the same protocol. Write once, expose everywhere.
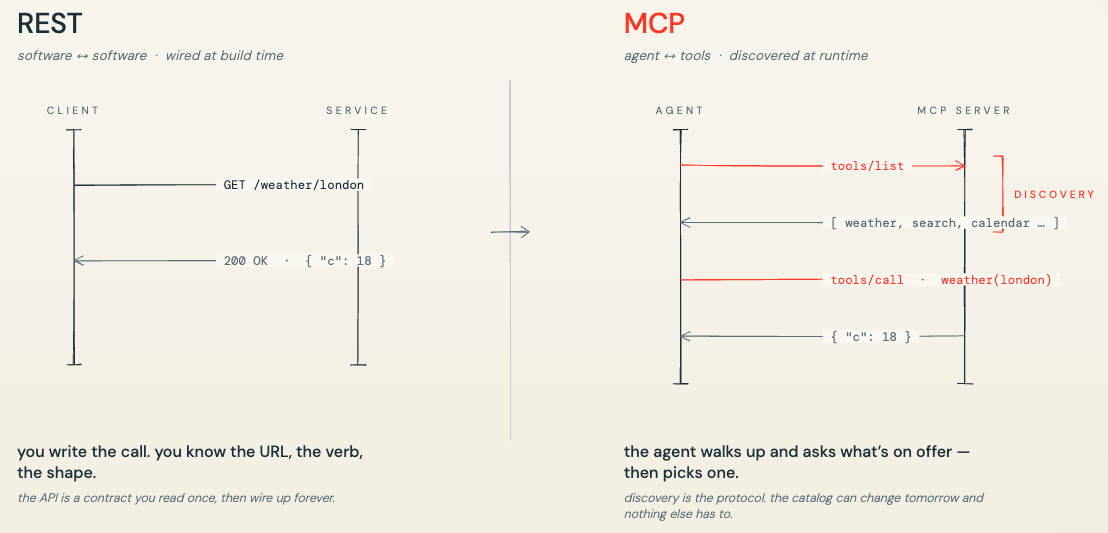
This is what happened when REST became the default for web APIs in the early 2000s, displacing the chaos of SOAP, WSDL, and proprietary RPC formats. REST won because it was simple enough that teams could independently build to the same standard and have things actually work. MCP is attempting the same move at the agent-tool layer.
Runtime capability discovery changes the architecture
One of the underappreciated features of MCP is the tools/list endpoint. Think of it like DNS for tools - you don’t hardcode IP addresses into your application, you resolve them at runtime. An agent queries the server on startup, gets a schema-described list of available tools, and decides which to invoke based on the task. Your agent architecture can evolve without redeployment every time a tool is added or changed.
Where it genuinely shines
MCP is strongest when the problem is standardised access to well-defined internal systems. Four use cases stand out:
Internal tool registries. A platform team builds and owns MCP servers for canonical internal capabilities - search, data retrieval, workflow triggers. Agent teams consume them without needing to understand the underlying integration. The boundary is clean, the ownership is clear, and the interface is versioned. This is the internal developer platform model applied to agent tooling.
Governed data catalogue access. An agent needs to query dataset metadata, lineage, or schema. Exposing a data catalog (Unity Catalog, Alation, Collibra, DataHub) via MCP gives the agent a structured, permissioned interface without direct database access. The server enforces what the agent can see. This matters enormously in financial services, where an agent browsing raw schema can inadvertently surface data it has no business touching.
Regulated workflow triggers. An agent initiates a downstream process - raises a ticket, submits a form, triggers a notification. MCP provides a typed, auditable interface for those triggers. The tool schema documents exactly what inputs are required; the server enforces them. The schema is the contract.
Multi-agent orchestration. A supervisor agent delegates to specialist subagents, each with its own MCP server exposing its capabilities. The supervisor discovers what each subagent can do and orchestrates accordingly. This is where capability discovery really earns its keep; it makes composition between agents tractable without tight coupling.
Tool Design for LLM Token Efficiency. The effectiveness of a tool is measured by its use within the LLM's context window. Prioritize tool interfaces that minimize the total volume of tokens consumed. For instance, prefer a
search_datasets(query: str)tool to a genericlist_all_datasets()tool. Furthermore, design tools with parameters for pagination and truncation to ensure the tool output - the data returned to the LLM is as concise and high-signal as possible. Refer to Anthropic’s blog: Writing effective tools for agents — with agents
A minimal MCP server for a governed data catalog wraps your catalog API behind a typed search_datasets tool enforcing domain filters, capping result limits, and keeping the agent away from raw schema access entirely. The tool definition is the contract; the server enforces it.
This is MCP doing what it’s designed for.
What risks MCP brings?
MCP moves fast to production. The failure modes tend to follow shortly after because the protocol makes it easy to ship something that works in a POC before the operational questions have been answered.
These are the five patterns you should understand.
Developers often forget “credential best practices”
Hardcoded credentials are not a new problem. What MCP changes is the rate at which new service boundaries get created. Spinning up an MCP server takes minutes - a few lines of Python, a decorator, done. That speed means teams are creating new integration points faster than their credential management habits have been built to handle. The result is more hardcoded credentials, in more places, with less visibility than traditional integration patterns would produce.
In a UK financial institution, this creates obligations that a missing credential policy would directly fail to meet under the Digital Operational Resilience Act (DORA). A credential with no owner and no rotation policy fails that bar.
DO NOT DO THIS: hardcoded credential in MCP server
DATABASE_URL = “postgresql://svc_agent:SuperSecret123@prod-db:5432/customers”The credential is now wherever this server runs. If the server is containerised, the credential is in the image or the environment. If the image is pushed to a registry, it may be in the layer history. The blast radius of a compromise is the entire downstream system, not just the agent. This is the digital equivalent of writing your vault combination on a Post-it and sticking it to the outside of the vault.
Models usually have access to every tool in an MCP server - this is not least priviledge
MCP puts tool invocation decisions in the hands of the model. The model reads the tool schemas, decides which tool to call, and constructs the arguments. Nothing in the base protocol validates whether that decision was appropriate, whether the arguments are safe, or whether the calling agent had the entitlement to invoke that tool for that user in that context.
This is Saltzer and Schroeder’s principle of least privilege - articulated in their 1975 paper “The Protection of Information in Computer Systems” and still the foundation of access control design.
The principle states that every component should operate with only the permissions it actually needs. A model that has access to every tool in an MCP server, for every user, at all times, is a maximal privilege configuration. It is the opposite of least privilege.
In regulated industries, this matters concretely. An agent that can invoke a transfer_funds or update_credit_limit tool should not be making that invocation based solely on what the model infers from a user message. The trust chain is broken.
python
# Dangerous: model output routes directly to tool execution
async def run_agent(user_message: str, user_id: str):
response = anthropic_client.messages.create(
model=”claude-sonnet-4-20250514”,
tools=mcp_tools, # All tools. No entitlement check. No context.
messages=[{”role”: “user”, “content”: user_message}]
)
for block in response.content:
if block.type == “tool_use”:
# The model decided. The server executes. Nothing in between.
result = await mcp_session.call_tool(block.name, block.input)
This code grants the model access to all tools (tools=mcp_tools), establishing a maximal privilege configuration. The model’s tool\_use block is immediately trusted as the final decision, bypassing any policy or validation check. Execution proceeds directly to mcp\_session.call\_tool without confirming the user’s entitlement or context.
The model is a reasoning engine. It is not a policy engine. These are different things, and conflating them is how you end up with agents doing things nobody authorised them to do.
MCP invocations still require explicit instrumentation to be traced end‑to‑end
Any RPC to a separate process requires explicit instrumentation to appear in your trace - that is not unique to MCP. What makes MCP different is that the protocol is new enough that most observability platforms have no native integration for it yet. With a mature HTTP or gRPC stack, there is a reasonable chance your tracing library auto-instruments at the transport layer. With MCP, there is not. Teams adopting it now are on their own.
An MCP tool call is an RPC to a separate process. Without explicit instrumentation, that call disappears from your trace. You can see the model’s input and output. You cannot see which tool was called, with what arguments, what the server returned, how long it took, or whether it failed. This is the observability equivalent of a black box flight recorder that stops recording five minutes before the crash. You have most of the data. You’re missing exactly the part that matters.
For regulated deployments, this is an audit problem. The FCA’s Senior Managers and Certification Regime (SM&CR) creates personal accountability for outcomes. If an agent made a decision that affected a customer - a credit flag, a document retrieval, a workflow trigger - and that decision was influenced by a tool call, you need to reconstruct exactly what the tool returned. If the tool call isn’t in your trace, you cannot reconstruct it. “The model did it” is not an explanation that satisfies a regulator.
The fix lies in instrumentation at the MCP boundary, not inside the server. This is shown in the MCPGateway pattern below.

Every team builds one, no one owns them - there is no established governance for MCP servers
In a large organisation, the absence of a shared standard is a vacuum that teams fill independently - each making a locally rational decision that creates a globally irrational system.
The MCP equivalent: without governance, every team designs its own simple system. The risk team builds an MCP server for their data warehouse. The finance team builds a different MCP server for the same data warehouse with different auth. The platform team builds a third server that partially overlaps with both. The agent now sees twelve tools that do variations of the same thing. The people who built them have moved on. No deprecation path exists. This is not a hypothetical - it is the same pattern that played out with internal REST APIs at most large organisations that adopted microservices without a service catalogue, and it is already starting to repeat with MCP.
The structural cause is Hyrum’s Law: observed by Google engineer Hyrum Wright and now widely referenced in software engineering: “With a sufficient number of users of an API, it does not matter what you promise in the contract — all observable behaviours of your system will be depended on by somebody.”
Once a team starts using your MCP server, they will depend on its undocumented behaviours. Deprecating it without governance becomes painful very quickly.
Treating MCP servers as infrastructure from the first deployment - with an owner, a version, a changelog, and a deprecation policy is not bureaucracy. It is the thing that lets you move fast in two years without digging out from under your own sprawl.
MCP doesn’t answer the data residency question
MCP doesn't answer the data residency question, and neither should it, but because MCP makes it trivially easy to spin up a new server anywhere, teams are creating new data residency exposure points faster than they're tracking them.
This is the failure mode that almost never appears in ecosystem documentation and is the one most likely to cause a material incident in regulated industries.
When an agent calls an MCP tool, data flows in both directions: the arguments sent to the tool, and the response returned. In a regulated context, both can contain customer data, personally identifiable information, or material non-public information. The question of where that data flows - which process handles it, which logs capture it, which jurisdiction it transits through - is not answered by the protocol. That is not a criticism of MCP. It is simply a boundary you need to understand.
The MCP server is a process. That process can run anywhere. If it runs in a container in a region that is not approved for the data it is handling, you have a data residency violation before the tool even returns a result. If the tool call arguments are logged by intermediary infrastructure before reaching your server, you have a data handling question that needs a documented answer.
For UK firms post-Brexit, this intersects with UK GDPR, FCA data governance expectations, and potentially the location requirements of your outsourcing arrangements. The compliance question is not “does MCP support data residency?” - it does not operate at that layer - but “can you trace every byte of this tool call, confirm where it went, and show it never left an approved boundary?”
That answer requires mapping the full data flow before deploying any MCP server that touches regulated data. Not after the first incident.
Do you actually need MCP?
I see it commonly - every team jumps to the conclusion of using MCP very fast. MCP is infrastructure and infrastructure has a cost - operational overhead, governance burden, complexity. The Unix philosophy, articulated by Doug McIlroy in the early 1970s, puts it plainly: “Write programs that do one thing and do it well.” Before you introduce a protocol for interoperability, ask whether you actually need interoperability.
Here is a decision tree I like to use to help teams make that decision:
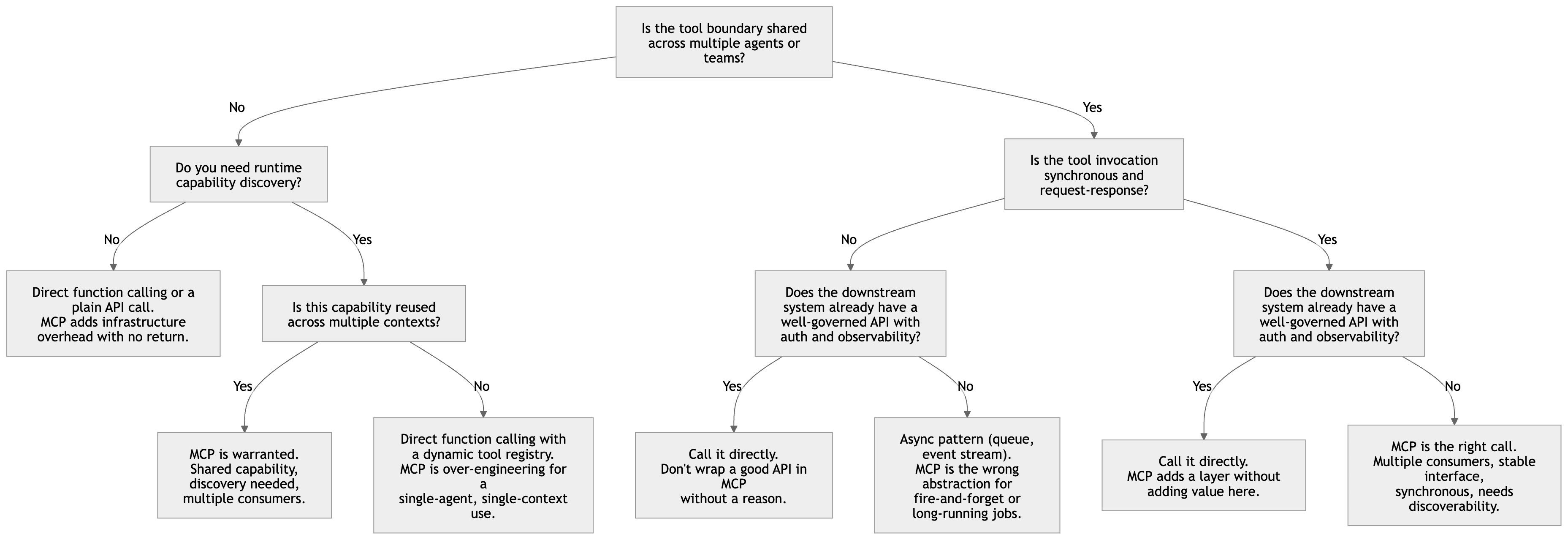
Let’s make each branch concrete.
When direct function calling is the right answer
If you have a single agent, a small number of tools, and no requirement for reuse across teams or frameworks, native function calling in the Anthropic SDK is simpler, cheaper, and easier to observe. No additional process boundary. No MCP server to maintain. No capability discovery overhead. Adding an MCP server here is the software equivalent of installing industrial plumbing to fill a kettle.
When a well-governed existing API beats MCP
If the downstream system already has a REST or gRPC API with proper authentication, rate limiting, observability, and documentation - a Salesforce API, an internal risk platform, a data catalogue with its own REST interface, wrapping it in an MCP server often adds a layer without adding value.
The test is simple: does the MCP layer provide something the existing API does not? If the answer is capability discovery for agent consumption, standardised schema, or unified access across multiple systems, MCP earns its keep. If the answer is “it’s just a wrapper,” you’ve added a process boundary, a deployment artefact, and an operational dependency for no functional gain.
When an async pattern is the right architecture
MCP is synchronous request-response. The agent calls a tool, blocks, and waits. That is fine for fast, bounded operations. It is the wrong shape for long-running jobs (submit and poll, not block), audit-required fire-and-forget (a message queue with dead-letter handling gives you durability and replay that MCP cannot), and event-driven workflows where the agent should be consuming from a stream, not polling in a loop.
MCP solves a specific problem well. The mistake is treating it as the default integration pattern for anything agent-related, rather than the right answer to a specific architectural question.
One pattern that works
Let me show you an architecture pattern to address these failure modes above. First, let’s understand the few best practice that matter here. It a bit of recap, but worth a refresh.
MCP servers are infrastructure, not glue code. You need an owner, you need versioning, changelog, deprecation policy. It should be registered in your internal catalogue and deployed through the same pipeline as your other services.
“Who owns this MCP server?” should have a human name attached to it.Every tool call must be observable. Instrument at the boundary - in the layer between the orchestrator and the MCP session - not inside the server. The instrumentation wrapper is shared infrastructure, not something each team spends time re-implementing.
The model never touches credentials or entitlements directly. There is always an authorisation layer between the model’s invocation decision and the tool’s execution. This is not optional in a regulated environment. It is least privilege applied at the agent layer.
Credentials are runtime injection, not baked-in secrets. Retrieve credentials at server startup via your secrets manager (AWS Secrets Manager, HashiCorp Vault, Azure Key Vault) - never at image build time, never from environment variables baked into a container. The credential is never in your code, never in your image layer history, and has a documented owner and rotation policy. Rotation is handled by the secrets manager; the server picks up new credentials on the next startup cycle.
Define quality before deployment using Evals. The observability focus in production must be preceded by rigorous quality assurance during development. And these ar enot unit tests - you need systematic measurement of the LLM's ability to use the tool correctly. Advocate for comprehensive evaluation tasks grounded in complex, real-world scenarios to measure tool efficacy. For debugging, run these evaluations programmatically, instructing agents to output their reasoning steps alongside the tool invocation. This practice helps developers probe exactly why an LLM selects or struggles with specific tools, ensuring the quality of the non-deterministic contract before it is exposed to regulated production environments.
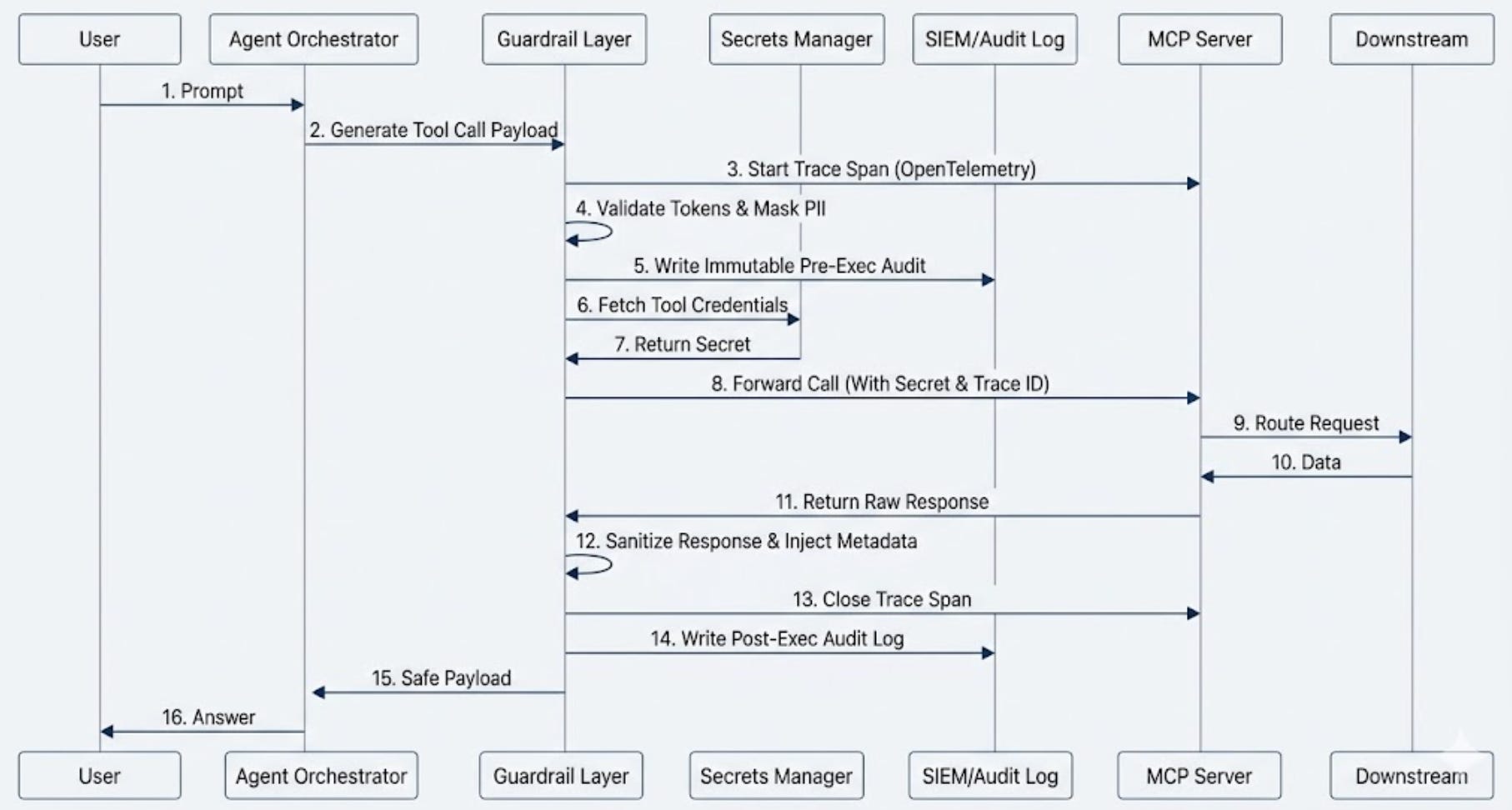
Every tool call passes through the Guardrail Layer before it gets anywhere near the MCP server. That layer validates tokens, masks PII, fetches credentials from the Secrets Manager at runtime, and writes an immutable audit entry before execution starts. The MCP server receives a clean, credentialled, traced call. The response comes back, gets sanitised, and the trace span closes. The user gets a safe payload. Nothing touches the downstream system without a paper trail.

Conclusion
MCP is the right abstraction at the right layer. The standardisation problem it solves is real, and the use cases where it works well are genuinely valuable enterprise problems. The protocol is not the issue.
What history tells us from USB to REST to microservices is that good protocols get adopted faster than the discipline to deploy them safely.
That gap is where incidents come from. This is commonly described as the difference between a sharp knife and a blunt one: the sharp knife is more dangerous in the wrong hands, but it’s the right tool for someone who knows what they’re doing.
The teams that get this right usually ask the boring questions first - who owns this, where does the data go, what happens when this call fails at 2am - and build systems accordingly.
That’s not caution. That’s just engineering.
Using or building with MCP?
Don't let speed compromise security. Apply the governance and architectural rigor outlined here to your MCP servers now. Build your Authorization and Observability Layer first to ensure your tool calls are secure, auditable, and compliant from day one.
Tell me in comments whether this resonates, what other challenges are you facing, and where did MCP do the magic for you. I am eager to learn from your experience - so please comment, leave a feedback.
P.S. If you’re new here - welcome 🎉. AgentBuild is a community of practitioners working through the real challenges of getting AI into production inside large organisations. Every week I share practical, grounded thinking from the people doing this work at the sharp end. The goal is never theory - it’s always: what can you use Monday morning.
Ask your friends to join.
More valuable content coming your way.
Thanks for reading agentbuild.ai! Subscribe for free to receive new posts and support my work.